Problem
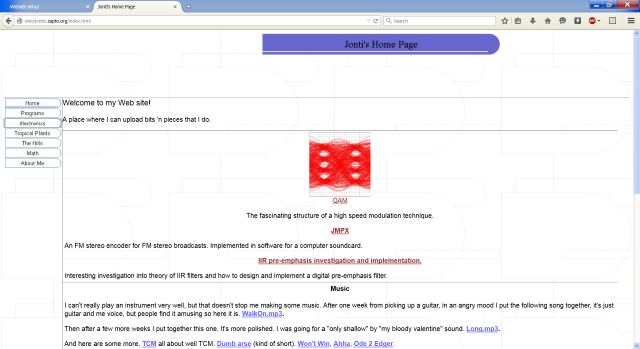
Old website main page
Initially my main website was created with FrontPage. FrontPage was a program by Microsoft for creating entire websites and now no longer exists. Microsoft pulling the rug out from underneath my feet on FrontPage meant I could no longer easily change content. I never even attempted to alter the menus. On Firefox some text would be invisible. Needless to say I was unhappy with Microsoft. It made me realize how important it was not to rely solely on one colsed proprietary the system for content authoring. I desired a method I could write and organize my website easily using any program I had on hand. I didn't want to rely on any organization or be particularly tied down to one piece of software.
My solution
I decided to go for a dynamically created web pages. This is in contrast to how FrontPage did it where all pages were static. A dynamic webpage is one where the webpage requested by the user on the host computer is assembled by the Web server on-the-fly before being returned to the user. The downside of this is the Web server has to do a lot more work than simply returning a file on the computer. The upside is the Web server can extract content from files and piece them together so as to return a webpage that has a consistent theme and style. Say for example you have written a webpage that has a particular style that doesn't match your website and you want to use this webpage in your website without having to open this webpage and make any modifications on. With dynamically created content the server can extract the content from the style and then include that content within the webpage that has the correct theme and style of your website. That would mean you could write your content in plain text, markdown, HTML, etc. However, each format would require a program to extract the content from the file. This being the case I chose to focus just on HTML content.
Inner workings
While I assume most people would use PHP, I used server-side includes and Perl CGI. Partly because I don't have PHP installed and partly I've used Perl before. The figure below shows how the webpage index.html request is processed by the Web server and the webpage that is returned to the host's web browser.
sequenceDiagram
Web browser->>Web Server: index.html req
Web Server->>layout.shtml: index.html req
layout.shtml->>unencaps.pl: index.html req
unencaps.pl->>Web Server: menu.html(SSI) req
Web Server-->>unencaps.pl: menu.html
unencaps.pl-->>layout.shtml: body of index.html
layout.shtml->>Web Server: menu.html req
Web Server-->>layout.shtml: menu.html
layout.shtml->>Web Server: index.html.shtml req
Web Server-->>layout.shtml: index.html.shtml
layout.shtml-->>Web browser: composite page
Sequence that index.html is retrieved once the host asks for it
The only access of files on the computers is performed by the Web server itself. When the unencaps.pl Perl file makes a request to the Web server for index.html it's sets it's referral agent to "SSI inclusion" so as to prevent an infinite loop. layout.shtml combines everything together to produce one page. unencaps.pl extracts the content of the HTML file simply by discarding every think about what lies within the body tag. unencaps.pl could be extended to extract and format into HTML from other formats such as markdown but that would've required more programming.
The index.html.shtml file contains page specific page related information such as title, header, CSS, JavaScript and so on, specific to the page itself. The menu.html file contains the unordered list items that is the menu bar contents. The index.html file contains the Main human readable content for the page.
Setup
Like most people my Web server runs the Apache Web server. The following four collapsible accordions more or less detail the code I used. If you find a security flaw please let me know.
Apache cgi-bin configuration in apache.conf file
ScriptAlias /cgi-bin/ /usr/lib/cgi-bin/
<Directory "/usr/lib/cgi-bin">
AllowOverride None
Options +ExecCGI -MultiViews +SymLinksIfOwnerMatch
Order allow,deny
Allow from all
#forbid http connections to unencaps.pl cgi file (only included in shtml will work).
RewriteEngine On
RewriteBase "/"
RewriteCond %{REQUEST_URI} unencaps.pl
RewriteCond %{SERVER_PROTOCOL} HTTP
RewriteRule "." "-" [F,END]
</Directory>
Apache directory configuration in apache.conf file
#add SSI
AddType text/html .shtml
AddOutputFilter INCLUDES .shtml
<Directory /var/www/html>
SSILegacyExprParser on
Options Indexes FollowSymLinks Includes
AllowOverride FileInfo
Require all granted
#default index page
DirectoryIndex /layout.shtml?req=index.html
#init
RewriteEngine On
RewriteBase "/"
#what happens when someone tries to load an html file
RewriteCond %{IS_SUBREQ} false
RewriteCond %{REQUEST_FILENAME} -f
RewriteCond %{REQUEST_FILENAME}.shtml -f
RewriteCond %{REQUEST_URI} ^(.*)\.html$ [NC]
RewriteCond %{HTTP_REFERER} !^SSI\ inclusion$ [NC]
RewriteRule ^(.*)\.html$ /layout.shtml?req=%{REQUEST_URI} [END,NC]
#forbid direct access to layout.shtml
RewriteCond %{IS_SUBREQ} false
RewriteCond %{REQUEST_URI} ^\/?layout\.shtml$ [NC]
RewriteRule "." "-" [F,END]
</Directory>
layout.shtml file that puts everything together
<!--#set var="file" value="" -->
<!--#if expr="$QUERY_STRING = /req=(.*)&?/" -->
<!--#set var="file" value="$1" -->
<!--#endif -->
<!--#set var="filenamebase" value="" -->
<!--#if expr="$file = /(.*).html$/" -->
<!--#set var="filenamebase" value="$1" -->
<!--#endif -->
<!--#set var="actualfile" value="$file" -->
<!--#if expr="$file = /\/(.*)$/" -->
<!--#set var="actualfile" value="$1" -->
<!--#endif -->
<!--#set var="path" value="" -->
<!--#if expr="$file = /(.*)\//" -->
<!--#set var="path" value="$1" -->
<!--#endif -->
<!--#set var="title" value="$filenamebase"-->
<!--#set var="headder" value="<h1 style=\"text-transform: capitalize\">$filenamebase</h1>"-->
<!--#set var="metafile" value="$file.shtml" -->
<!--#if expr="$file = /\/(.*)$/" -->
<!--#set var="metafile" value="$1.shtml" -->
<!--#endif -->
<!--#config errmsg="SSI Error"-->
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="description" content="Jonti's Web Site">
<link rel="stylesheet" href="/css/mystyle.css">
<!--#include virtual="$metafile" -->
<title><!--#echo var="title"--></title>
</head>
<body>
<div id="layout">
<div id="my-menu-container">
<div class="my-menu">
<div class="my-menu-heading">Menu</div>
<ul class="my-menu-list">
<!--Include menu items-->
<!--#include virtual="/menu.html" -->
</ul>
</div>
</div>
<div id="main">
<div class="header" id="linearBg2">
<!--include a headder-->
<!--#echo encoding="none" var="headder"-->
</div>
<div class="content">
<!--include main content-->
<!--#set var="unencapsulatecgi" value="/cgi-bin/unencaps.pl?req=$file" -->
<!--#include virtual="$unencapsulatecgi" -->
</div>
<div class="margined"><div class=" modificationdate">Jonti. Last modified <!--#flastmod virtual=$actualfile -->.</div></div>
</div>
</div>
</body>
</html>
Perl file to extract just the HTML body
#!/usr/bin/perl -wT
use strict;
use CGI;
local $/ = undef;
my $query = new CGI;
my $req = $query->param('req');
my $baseloc = $query->url(-base => 1)."/";
if (!defined $req)
{
print "Content-type: text/html\n\n";
print "Error 234\n";
exit;
}
if ($baseloc =~ /^included:\/\/(.*)/)
{
$baseloc="http://".$1;
}
else
{
print "Content-type: text/html\n\n";
print "No direct calls. Can only be called called by SSI\n";
exit;
}
if ($req =~ /:/)
{
print "Content-type: text/html\n\n";
print "No absolute paths allowed\n";
exit;
}
if ($req =~ /\/*(.*)/)
{
$req=$1;
}
$req=$baseloc.$req;
my $document=`/usr/bin/curl --referer "SSI inclusion" -so - "$req"`;
if (!defined $document)
{
print "Content-type: text/html\n\n";
print "Error 123\n";
exit;
}
$document =~ s/^((.|\n)*?)<( )*?body(.)*?>//i;
$document =~ s/<[ ]*?\/[ ]*?body[ ]*?>((.|\n)*?)$//i;
print "Content-type: text/html\n\n";
print $document;
CSS
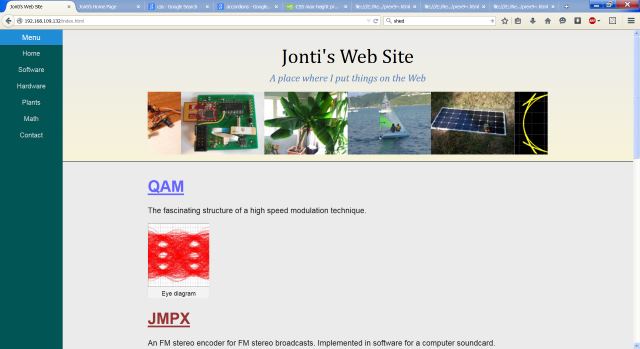
New website main page
The mantra these days is to keep the webpage style separate from the webpage content. This allows changing the style of a website without having to alter any of the files that contain content. The style is kept in CSS files, where CSS is an acronym for Cascading Style Sheets. These CSS files get loaded by the web browser as well as the wanted page such as index.html.
Redesigning this website I thought it would be a good experience to learn a little basic CSS in the process. Up until now I just left it for other computer programs to figure out. I didn't just want to use someone else's CSS files and tried instead to make my own. I have however used other CSS files as well as mine to create Web site style. The other CSS files seem to fix various layout bugs I couldn't seem to figure out how to solve. While I don't think I could really ever get too enthusiastic with CSS programming it was an interesting experience.
I wanted a plain and simple themed website. I chose a vertical menubar because as screens get wider this seems to be a lot of wasted space and it's hard to read content that is too wide. When the web browsers width goes below 48 the characters the menu bar then becomes a horizontal one at the top of the screen. My idea here is that this should make my website viewable on mobile devices but I haven't doing so yet.
JavaScript
JavaScript allows code to be run on the host computer to do complicated abstract tasks. Generally I have shied away from using JavaScript as it requires the host computer to be running JavaScript, and due to different web browsers is very hard to know exactly what each user sees. Also I prefer the idea of content being served rather than the web browser having to do its own duty work. An exception to the lack of JavaScript I use is the page. This page uses a lot of JavaScript. It uses JavaScript for code highlighting, the accordions, and the grpahs. However, in passing I tried Jquery mobile ui which comprises both CSS and JavaScript to produce some very professional looking websites with very little effort; interesting but not for me.
graph LR;
HTML(HTML )-->webbrowser(Web Browser )
CSS(CSS )---HTML
JavaScript(JavaScript)---HTML
When loading a web page, CSS files and Javascript files often get brought along for the ride. CSS contains the style you see while Javascript alows for more complicated tasks such as drawing this graph you see here (it's not loaded as an image).
Ummm, Take two
This method of dynamic webpage creation was a bit convoluted and was rather restrictive. Having a separate meta file for every webpage meant including pages that had already been created using other applications was a hassle. So I decided to remove the server-side includes and write a Perl file that would be entirely responsible for page generation. The Perl file could then create dynamic pages even if the metafile was not included. It could also cache the dynamic pages so pages wouldn't have to be regenerated for each request. The following shows what happens when a request for the page index.html happens.
sequenceDiagram
Web browser->>Web Server: index.html req
Web Server->>layout.pl: index.html req
alt if index.html is modified
Note right of layout.pl: Create page<br/>Cache page
layout.pl-->>Web Server: composite page (live)
else otherwise
layout.pl-->>Web Server: composite page (cached)
end
Web Server-->>Web browser: composite page
New sequence that index.html is retrieved once the host asks for it
The perl file now need access to the disk content. In particular write access to the cache. This I imagine is somewhat of a security problem as it could potentially allow cache poisoning. As well as Apache forbidding direct access to the Perl file and making sure that the file exists before calling the perl file, I've included general checks to hopefully make sure that no one circumvents the intended use of the Perl file. The file itself is given below.
Perl file layout.pl for new method of dynamic content creation
#!/usr/bin/perl -w
use strict;
use CGI qw(:standard);
use File::stat;
use Date::Format;
use constant CACHEDIR => "/var/cache/apache-cache";
local $/ = undef;#in
if ((!defined $ENV{REQUEST_URI})||(!defined $ENV{SCRIPT_NAME}))
{
print "Needs to be run from apache web server\n";
exit;
}
my $query = new CGI;
my $req = $ENV{REDIRECT_URL};
my $filename = $query->param('filename');
my $baseloc = $query->url(-base => 1)."/";
#disable direct calls
if($ENV{REQUEST_URI} =~ /$ENV{SCRIPT_NAME}/)
{
send403();
exit;
}
if ($ENV{REDIRECT_STATUS} ne "200")
{
send403();
exit;
}
if ((!defined $req)||(!defined $filename))
{
print "Content-type: text/html\n\n";
print "Error need a request and filename\n";
exit;
}
if ($req =~ /:/)
{
print "Content-type: text/html\n\n";
print "No absolute paths allowed\n";
exit;
}
if ($req =~ /\.\./)
{
print "Content-type: text/html\n\n";
print "No dots allowed\n";
exit;
}
if ($filename =~ /:/)
{
print "Content-type: text/html\n\n";
print "No absolute paths allowed\n";
exit;
}
if ($filename =~ /\.\./)
{
print "Content-type: text/html\n\n";
print "No dots allowed\n";
exit;
}
if ($req =~ /\/*(.*)/)
{
$req=$1;
}
my $cachefilename=CACHEDIR."/".$req;
my $cachedirname=$cachefilename;
if ($cachefilename =~ /(.*)\//)
{
$cachedirname=$1;
}
else
{
print "Content-type: text/html\n\n";
print "Invalid cache directory\n";
exit;
}
if( !-e $filename )
{
print "Content-type: text/html\n\n";
print "File does not exist\n";
exit;
}
my $same=0;
my $name;
if($filename =~ /([^\/]*)$/)
{
$name=$1;
if($req =~ /([^\/]*)$/)
{
if ($1 eq $name)
{
$same=1;
}
}
}
if (!$same)
{
print "Content-type: text/html\n\n";
printf "not the same files\n";
exit;
}
#get time main file was last modified in string format
#Sat, 27 Apr 2013 00:44:54 GMT <-- format needed on apache for http header to work
my $lastmodified = time2str( "%a, %e %b %Y %X GMT", (stat($filename)->mtime) ,"GMT");
#if cache file exists and is new then use it instead of dynamically creating page
if( -e $cachefilename )
{
#if cache is newer than live file
if (-M $cachefilename <= -M $filename)
{
#read cache
if(open(my $fh, '<', $cachefilename))
{
#print http header
print "Last-Modified: ".$lastmodified."\n";
print "Content-type: text/html\n\n";
#print page
#print "cached\n";
#print "<!-- cached-->";
print <$fh>;
close $fh;
exit;
}
else
{
print "Content-type: text/html\n\n";
print "Can't open cache\n";
exit;
}
}
}
#create and cache page as page has changed or is not cached
#read menu file
my $menu;
if(open(my $fh, '<', $ENV{DOCUMENT_ROOT}."/menu.html"))
{
$menu=<$fh>;
close $fh;
}
else
{
print "Content-type: text/html\n\n";
print "Can't open menu\n";
exit;
}
#read main file
my $document;
if(open(my $fh, '<', $filename))
{
$document=<$fh>;
close $fh;
}
else
{
print "Content-type: text/html\n\n";
print "Can't open main file\n";
exit;
}
my $removeheader=1;
my $include=1;
#extract metadata, title, jonti header, and jonti meta
my $head;
if($document =~ /(<head(.|\n)*?\/head>)/i)
{
$head=$1;
}
my @meta = $head =~ /(<meta.*?>)/ig;
my $title;
if($head =~ /(<title>.*?<\/title>)/i)
{
$title = $1;
}
my $header;
if($head =~ /<!--[ ]?jonti var="header" value="((.|\n)*?)"[ ]?-->/)
{
$header=$1;
$removeheader=0;
}
if($head =~ /<!--[ ]?jonti var="meta" value="((.|\n)*?)"[ ]?-->/)
{
push(@meta,$1);
}
if($head =~ /<!--[ ]?jonti var="no include"[ ]?-->/)
{
$include=0;
}
#if metafile exists then read that too, but wont recache if changed. cant be bothered to do that. just delete the cache.
my $dontaddtitle=0;
my $metadoc;
my $metafilename=$filename.".shtml";
if( -e $metafilename )
{
#read metafile
if(open(my $fh, '<', $metafilename))
{
#extract jonti meta and jonti header
$metadoc=<$fh>;
if($metadoc =~ /<!--[ ]?jonti var="header" value="((.|\n)*?)"[ ]?-->/)
{
$header=$1;
$removeheader=0;
}
if($metadoc =~ /<!--[ ]?jonti var="meta" value="((.|\n)*?)"[ ]?-->/)
{
push(@meta,$1);
if($1 =~ /(<title>.*?<\/title>)/i)#dont add title 2 times
{
$dontaddtitle=1;
}
}
if($metadoc =~ /<!--[ ]?jonti var="no include"[ ]?-->/)
{
$include=0;
}
close $fh;
}
else
{
print "Content-type: text/html\n\n";
print "Can't open metafile\n";
exit;
}
}
#if not to include then just cache and return org doc
if(!$include)
{
#print http header
print "Last-Modified: ".$lastmodified."\n";
print "Content-type: text/html\n\n";
#cache page for later
mkdir $cachedirname unless -d $cachedirname; # Check if dir exists. If not create it.
if(open(my $fh, '>', $cachefilename))
{
print $fh $document;
close $fh;
}
else
{
print "<!-- can't cache ".$!." -->";
}
#print page
print $document;
exit;
}
#extract body
$document =~ s/^((.|\n)*?)<( )*?body(.|\n)*?>//i;
$document =~ s/<[ ]*?\/[ ]*?body[ ]*?>((.|\n)*?)$//i;
if($removeheader)
{
push(@meta,"<style>.content img{max-width: 100%;height: auto;}.header{padding:0px !important;border-bottom: none;}</style>");
}
#add default description, charset and title if none found
my $description=0;
my $charset=0;
foreach my $metatag (@meta)
{
#print $metatag."\n";
if($metatag =~ /[ |;]name="description"/i)
{
$description=1;
}
if($metatag =~ /[ |;]charset=/i)
{
$charset=1;
}
}
if(!$description)
{
push(@meta , '<meta name="description" content="Jonti\'s Web Site">');
}
if(!$charset)
{
push(@meta , '<meta charset="utf-8">');#or maybe <meta charset="ISO 8859-1">
}
if (!defined $title)
{
$title="<title>".$name."</title>";
if($req =~ /([^\/]*)\./)
{
$title="<title>".$1."</title>";
}
}
if ($dontaddtitle)
{
$title="";
}
#form composite page
my $compositedoc = <<EOF;
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html lang="en">
<head>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="/css/mystyle.css">
<!--Include title and meta data-->
$title
@meta
</head>
<body>
<div id="layout">
<div id="my-menu-container">
<div class="my-menu">
<div class="my-menu-heading">Menu</div>
<ul class="my-menu-list">
<!--Include menu items-->
$menu
</ul>
</div>
</div>
<div id="main">
<div class="header" id="linearBg2">
<!--include a headder-->
$header
</div>
<div class="content">
<!--include main content-->
$document
</div>
<div class="margined"><div class=" modificationdate">Jonti. Last modified $lastmodified.</div></div>
</div>
</div>
</body>
</html>
EOF
#print http header
print "Last-Modified: ".$lastmodified."\n";
print "Content-type: text/html\n\n";
#cache page for later
mkdir $cachedirname unless -d $cachedirname; # Check if dir exists. If not create it.
if(open(my $fh, '>', $cachefilename))
{
print $fh $compositedoc;
close $fh;
}
else
{
print "<!-- can't cache ".$!." -->";
}
#print page
#print "live\n";
#print "<!-- live -->";
print $compositedoc;
sub send403
{
$ENV{REQUEST_URI} =~ /([^\?]*)/;
print "Status: 403 Forbidden\n";
print "Content-type: text/html\n\n";
print
'<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>403 Forbidden</title>
</head><body>
<h1>No No no: Forbidden</h1>
<p>You don\'t have permission to access '.$1.'
on this server.<br />
</p>
<hr>
'.$ENV{SERVER_SIGNATURE}.'
</body></html>';
}
As can be seen it's rather large but fairly simple in it's working. It correctly informs both Apache and the web browser the last time the underlying document was last modified. As of the 31st of August 2015 this is what I'm running on the site. Pages that I used Lyx to create such as PSK31 Perfomance Investigations so I could easily write down mathematical equations do not render particularly well so these pages of served as is.
I've also made a few adjustments in the CSS file to make the look of this website on mobile devices better (well on my phone anyway). I set up a 301 redirect on the paradise server using an ".htaccess" file and another 301 redirect on wwwjonti.zapto.org (which points to the same IP as jonti.zapto.org); now everything should go to jonti.zapto.org.
Jonti 2015
Home