A squelch application
This project is weird. Initially I was interested in using AI to detect if there was human voice in a signal with considerable noise. The noise would vary considerably over time so sometimes it would be difficult to detect if a human voice was actually there or not.
I tried some simple AI using some manually obtained samples for the algorithm to learn by. I had problems, the AI did not like it when the type of background noise would change such as noise that was not flat or would have interference in the form of sine waves. I wondered if AI was not really suited to the problem and if I could do better.
I had a look at clustering algorithms which would attempt to decide whether or not something was voice by treating the output of an FFT as a multidimensional point and creating two clusters as far away as possible. This sort of worked but I had problems if the sample audio didn’t contain any voice at which point the algorithms still tried to create clusters that didn’t actually exist.
Over time I paid less attention to voice and was more interested in noise and figuring out how to characterize it. I figured if I could get a good understanding of the noise floor it would be relatively easy to detect any change in and hence detect voice.
I tried linear predictive coding (LPC) and would take blocks of audio and then from that predict the future. This was really interesting. As voice is very complicated, LPC with the right settings can’t predict voice. I could totally remove voice and produce something that sounded to my ears like noise floor and any interference in the form of sign waves. However on closer inspection the noise floor had bumps on where the voice had been. So while interesting I moved on.
As I was interested in the noise floor I decided to investigate further and look more closely into what happens when a wanted signal is added to some random noise. I added together a sine wave with some White Gaussian Noise (WGN). I then performed short FFTs on it with overlap and a windowing function. The figure below shows my setup…
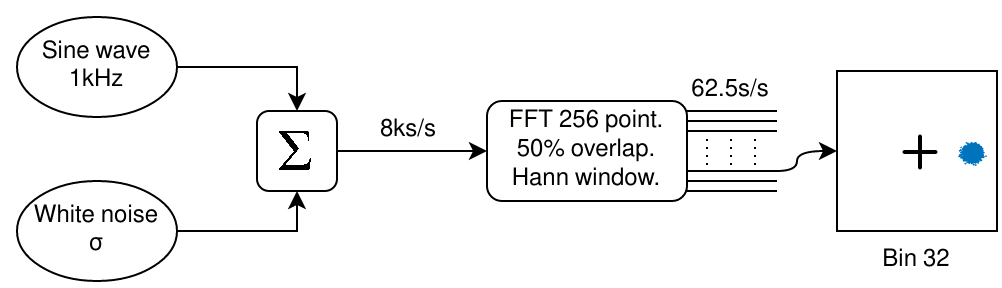 Block diagram of sine wave plus noise test signal through FFT
Block diagram of sine wave plus noise test signal through FFT
In this case bin 32 appears to have a blotchy disk of points offset from the center. However, if the sine wave frequency is a bit different you can get other results as can be seen in the following figure…
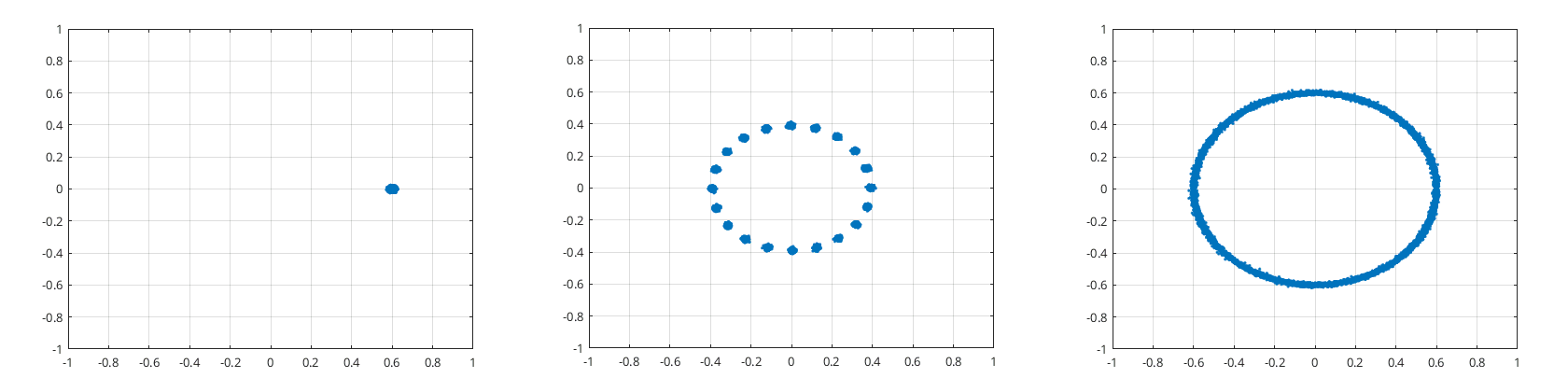 Slight change of sine wave frequency can make a big difference
Slight change of sine wave frequency can make a big difference
Primarily I am interested in figuring out the amplitude of the WGN that gets into bin 32. So that means can I figure out just by looking at bin 32?
When the disk is not spinning it looks like σ is probably going to be proportional to the dispersion of the disk. While when the disk is spinning and producing a circle around the origin then it looks like is probably going to be proportional to the thickness of the line that produces the circle.
Things get trickier when the noise gets bigger while the sine wave amplitude doesn’t…
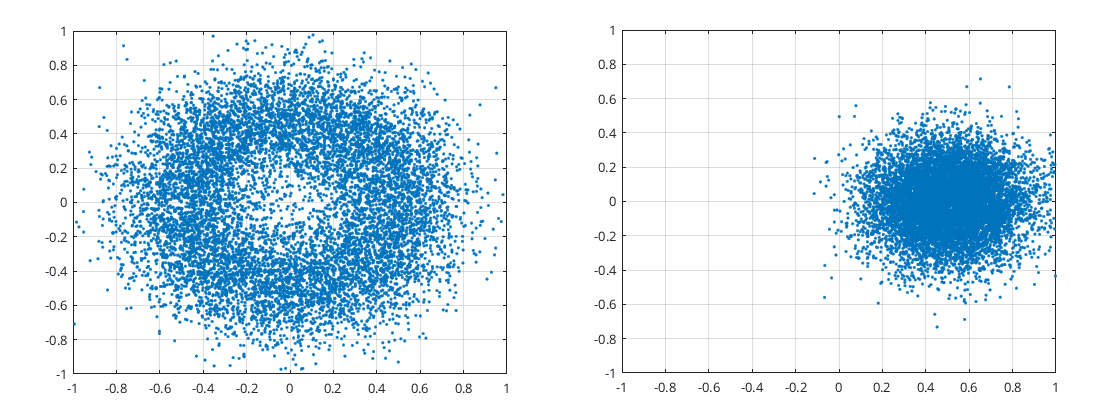 Sine wave amplitude μ=0.5 and noise σ=0.25: 1001 Hz and 1000 Hz respectively
Sine wave amplitude μ=0.5 and noise σ=0.25: 1001 Hz and 1000 Hz respectively
In this case when the disk is not spinning (1000 Hz) we can still work out the standard deviation σ from the dispersion of the disk. However when the disk is spinning (1001 Hz) it produces another disk even bigger whose dispersion is not the standard deviation we are looking for.
That the disk may or may not spin is a hassle. I can fix this problem by randomly spinning points thus having just one case to deal with, that of a spinning disk. This removes all phase information. As there is now no phase information the only measurement I can work with is the absolute value of any point. So the question becomes can I estimate the standard deviation from just the amplitude of the points?
The model
First off I need a model of what the points I’m looking at are after I have randomly spun each point; this is what I’m going to use…
Where and are normally distributed random variables with standard deviation of and is a uniformly distributed random variable between zero and one…
Does this model fit reality?
When I take the absolute value of it turns it into some sort of folded distribution. It’s sort of like a folded bivariate normal distribution but it has the strange radial offset caused by the sine wave. I tried looking for something on the Internet that mentioned this kind of distribution but couldn’t find something to help me.
I’m pretty sure this is a correct model to use. But just to be safe I compared some stats of the model with ones obtained via the FFT bin. The stats I looked at were all based on the absolute value and are donated by the subscript f. I looked at standard deviation, mean, and the skewness of the folded distribution and plotted this against the given non-folded standard deviation divided by the non-folded mean. The following figure shows a plot varying the standard deviation while keeping the mean fixed at 0.56…
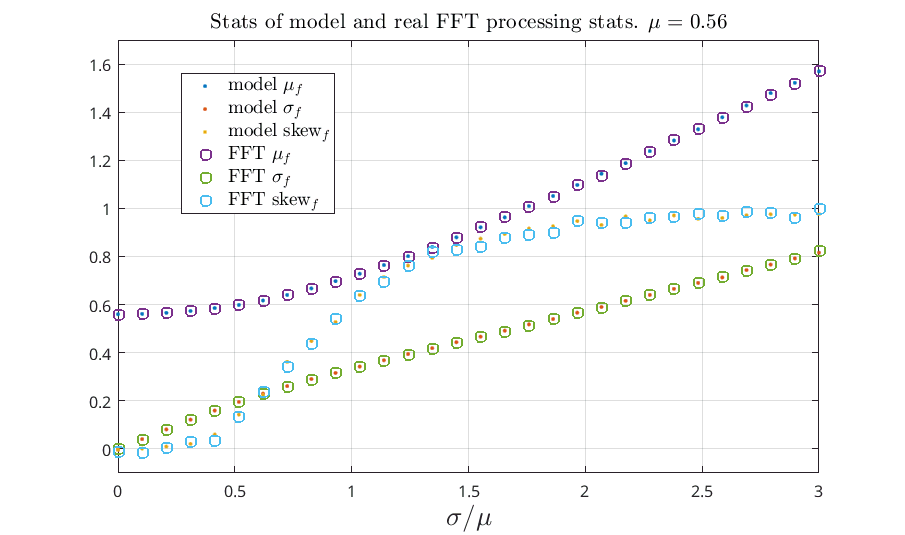 Comparing stats of folded distribution obtained from the model and through the FFT processing
Comparing stats of folded distribution obtained from the model and through the FFT processing
I had some scaling issues due to the FFT and the Hann window and calculated these values numerically. The skewness I scaled such that when the mean was zero the skewness would be one. The skewness scaling value was also obtained numerically.
The following Matlab code was used to obtain the previous figure...
close all;
clear all;
clc;
markersize=8;
linewidth=2;
NNN=100000;
mu=0.56;
sigma=0.25;
min_sigma=0.000001;
max_sigma=3*mu;
number_of_testpoints=30;
log_sigma=linspace(min_sigma,max_sigma,number_of_testpoints);
%%%%%%%%%%%%%%%%%
%testing model
if ~exist('log_sigma','var')
log_sigma=zeros(1,number_of_testpoints);
end
if ~exist('log_mu','var')
log_mu=zeros(1,number_of_testpoints);
end
if ~exist('log_mu_estimate','var')
log_mu_estimate=zeros(1,number_of_testpoints);
end
if ~exist('log_sigma_estimate','var')
log_sigma_estimate=zeros(1,number_of_testpoints);
end
if ~exist('log_muf','var')
log_muf=zeros(1,number_of_testpoints);
end
if ~exist('log_sigmaf','var')
log_sigmaf=zeros(1,number_of_testpoints);
end
if ~exist('log_skew','var')
log_skew=zeros(1,number_of_testpoints);
end
for k=1:number_of_testpoints
sigma=log_sigma(k);
%model
X=sigma*randn(NNN,1)/sqrt(2);
Y=sigma*randn(NNN,1)/sqrt(2);
W=rand(NNN,1);
y2=(X+1i*Y+mu*exp(1i*2*pi*W));
%abs
y2=abs(y2);
%calc stats from y2
muf=mean(y2);%folded mean
sigmaf=std(y2);%folded sigma
sku=(mean((y2-muf).^3)/(sigmaf^3))/0.6311245;%folded normalized skew
if(isnan(sku)) sku=1; end%in case sigmaf is zero
alpha=abs(sqrt(1-sku^2));%calc alpha from folded normalized skew
sigma_estimate=sqrt((((1+alpha))*mean(y2.^2)-alpha*2*mean(y2)^2));%calc sigma
mu_estimate=sqrt(muf^2+sigmaf^2-(sigma_estimate^2));%calc mu
log_sigma(k)=sigma;
log_mu(k)=mu;
log_sigma_estimate(k)=sigma_estimate;
log_mu_estimate(k)=mu_estimate;
log_muf(k)=muf;
log_sigmaf(k)=sigmaf;
log_skew(k)=sku;
end
log_sigma(isnan(log_sigma))=[];
log_mu(isnan(log_mu))=[];
log_sigma_estimate(isnan(log_sigma_estimate))=[];
log_mu_estimate(isnan(log_mu_estimate))=[];
log_muf(isnan(log_muf))=[];
log_sigmaf(isnan(log_sigmaf))=[];
log_skew(isnan(log_skew))=[];
x=(log_sigma./log_mu);
plot(x,log_muf,'.','MarkerSize',markersize,'LineWidth', linewidth);hold on;
plot(x,log_sigmaf,'.','MarkerSize',markersize,'LineWidth', linewidth)
plot(x,log_skew,'.','MarkerSize',markersize,'LineWidth', linewidth)
legend({'$\mu _f$','$\sigma _f$','skew$_f$'},'Interpreter','latex','FontSize',14);
set(gca,'FontSize',12)
xlabel('$\sigma / \mu$','Interpreter','latex','FontSize',20);
%%%%%%%%%%%%%%%%%
%looking at FFT output
log2_sigma=log_sigma;
if ~exist('log2_sigma','var')
log2_sigma=zeros(1,number_of_testpoints);
end
if ~exist('log2_mu','var')
log2_mu=zeros(1,number_of_testpoints);
end
if ~exist('log2_mu_estimate','var')
log2_mu_estimate=zeros(1,number_of_testpoints);
end
if ~exist('log2_sigma_estimate','var')
log2_sigma_estimate=zeros(1,number_of_testpoints);
end
if ~exist('log2_muf','var')
log2_muf=zeros(1,number_of_testpoints);
end
if ~exist('log2_sigmaf','var')
log2_sigmaf=zeros(1,number_of_testpoints);
end
if ~exist('log2_skew','var')
log2_skew=zeros(1,number_of_testpoints);
end
for idx=1:number_of_testpoints
sigma=log2_sigma(idx);
Fs=8000;%sample rate
block_size=256;%-->32ms blocks
scale=mean(hann(256));
y2=[];
wave_phase_offset=0;
m=0;%128+5
while (numel(y2)<NNN)
m=m+1;
x=sigma*randn(NNN,1)/19.6337;%noise. 19.6337 for scaling so that sigma is for noise in a bin.
sin_wave = mu*cos(2*pi*1000.00*[0+NNN*(m-1):(NNN-1)+NNN*(m-1)]'/Fs+wave_phase_offset)/128;%sine wave. 128 for scalling so the mu is for signal in bin.
%FFTs
for k=1:128:numel(x)-256%ffts are 50% overlapped
xb=(sin_wave(k:k+256-1)+x(k:k+256-1)).*hann(256);%signal is sine wave plus noise
XB=fft(xb);
XB=abs(XB);%abs of fft
y=XB(33)./scale;%looking just at bin 33 (8000*(33-1)/256=1000Hz)
y2(end+1)=y;
end
end
y2=y2(1:min(NNN,numel(y2)))';
%this is the alpha wanted to produce the correct sigma estimate
alpha_wanted=(sigma^2-mean(y2.^2))/(mean(y2.^2)-2*mean(y2)^2);
%calc stats from y2
muf=mean(y2);%folded mean
sigmaf=std(y2);%folded sigma
sku=(mean((y2-muf).^3)/(sigmaf^3))/0.6311245;%folded normalized skew
if(isnan(sku)) sku=1; end%in case sigmaf is zero
alpha=abs(sqrt(1-sku^2));%calc alpha from folded normalized skew
sigma_estimate=sqrt((1+alpha)*mean(y2.^2)-2*alpha*mean(y2)^2);%calc sigma
mu_estimate=sqrt(muf^2+sigmaf^2-sigma_estimate^2);%calc mu
log2_sigma(idx)=sigma;
log2_mu(idx)=mu;
log2_sigma_estimate(idx)=sigma_estimate;
log2_mu_estimate(idx)=mu_estimate;
log2_muf(idx)=muf;
log2_sigmaf(idx)=sigmaf;
log2_skew(idx)=sku;
end
log2_sigma(isnan(log2_sigma))=[];
log2_mu(isnan(log2_mu))=[];
log2_sigma_estimate(isnan(log2_sigma_estimate))=[];
log2_mu_estimate(isnan(log2_mu_estimate))=[];
log2_muf(isnan(log2_muf))=[];
log2_sigmaf(isnan(log2_sigmaf))=[];
log2_skew(isnan(log2_skew))=[];
x=(log2_sigma./log2_mu);
plot(x,log2_muf,'o','MarkerSize',markersize,'LineWidth', linewidth);hold on;
plot(x,log2_sigmaf,'o','MarkerSize',markersize,'LineWidth', linewidth)
plot(x,log2_skew,'o','MarkerSize',markersize,'LineWidth', linewidth)
legend({'$\mu _f$','$\sigma _f$','skew$_f$'},'Interpreter','latex','FontSize',14);
legend({'model $\mu _f$','model $\sigma _f$','model skew$_f$','FFT $\mu _f$','FFT $\sigma _f$','FFT skew$_f$'},'Interpreter','latex','FontSize',14);
title('Stats of model and real FFT processing stats. $\mu=0.56$','Interpreter','latex','FontSize',16);
grid on;
While it’s not a very rigorous way of seeing if the model fits reality it’s good enough for me and I am confident that the model fits reality.
I then started looking for ways to relate the statistics I could obtain from the folded distribution to that of the parameters that produce it and ...
OK if I figure out one of or I can get the other one, but I still can’t figure out how I get one of them; problem.
It was about by this point I wondered if my model over complicated for what I was trying to do. Initially I uniformly randomized the phase of the points so as to match real life. However I then ignored all the phase information and just looked at the absolute value of these points. As the variance in both the and directions is the same it implies that the variance of does not change with respect to that of the phase of . So if all I’m looking at is I can write a new model…
This produces a fuzzy disk to the right and doesn’t match the reality of the fuzzy disk randomly rotated around the origin. However the absolute value of these two random variables should be equal; so . I guess the proof would go something along the lines of…
This is probably the most dodgy part of the proof, while the random rotation of makes no difference to as is rotationally symmetric and is independent of the rotation, this rotation is the same rotation as used for . However is a constant so I guess that’s what it’s OK. So if you happy with that the rest of it would follow…
Hmmm, so if was incorporated into …
Then that would a bivariate normal distribution. Take the absolute value of that and that would be a folded bivariate normal distribution which I do remember seeing a paper written about but didn’t really look at it because I didn’t think it would apply. Oh well I will continue.
To make things easier I considered two extreme cases; one where σ was considerably larger than and the other where was considerably larger than .
When we can say that the standard deviation is about equal to . This comes about because, assume then...
or equivalently…
In this case there’s not really any signal to speak of and we just have a bivariate normal distribution with zero mean; it’s a bunch of points scattered around the origin.
When we can say that the standard deviation is about equal to . This time as sigma is much less than mu the random points are very unlikely to come close to the origin and fall back on itself so hence we can treat the points as a normal bivariate distribution. First look at in a graphical way where the dotted lines represent standard deviation in that direction…
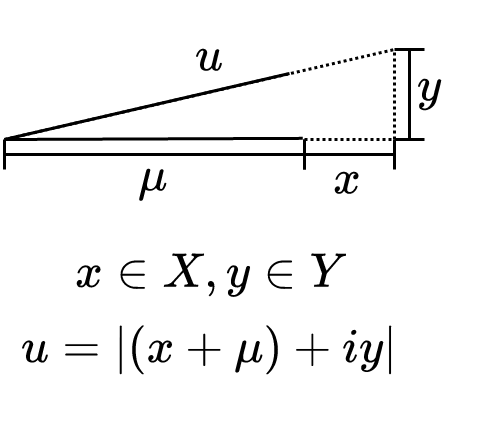 If σ is much smaller than μ
If σ is much smaller than μ
The first obvious thing is that most of the standard deviation of will come from the standard deviation of as the component can’t change the length of by much. Or the same thing in notation could be phrased as…
If then let’s take the limit as goes to infinity…
Again most of the standard deviation of comes from the standard deviation of when is big.
So when is small and is big then is about equal to , while when is small and is big then is about equal to . Therefore we can write the following equation for some unknown alpha that varies between zero and one…
There are other ways to write the same things such as…
or
When alpha is zero this equates to a small mu and a large sigma, while when alpha is one this equates to a large mu and a small sigma.
My next idea was to use the normalized skewness statistic to figure out what alpha should be. When the skewness would equal its maximum this would imply a mu of zero, while when skewness was equal to zero mu must be much larger than sigma. So I ran through some tests and plotted what the alpha had to be for various skewness statistics…
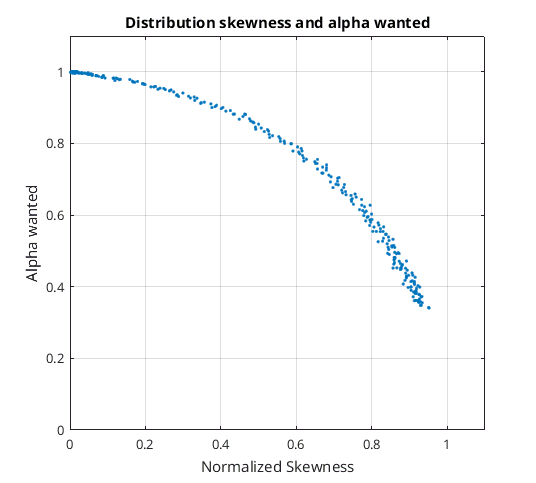 Distribution skewness and alpha wanted.png
Distribution skewness and alpha wanted.png
It looked like a quarter of a circle. To confirm that I squared and added together the skewness and the alpha wanted…
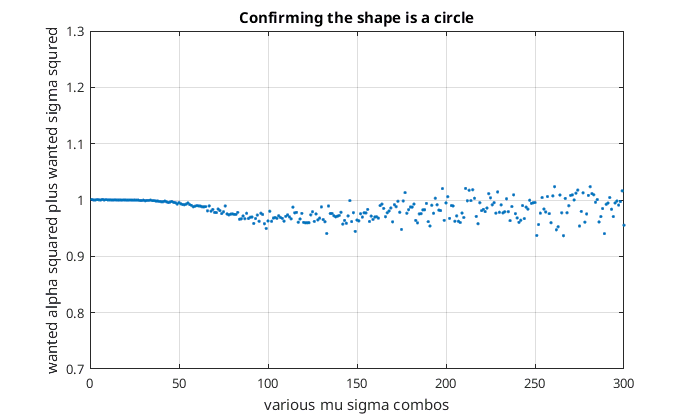 Confirming the shape is a circle
Confirming the shape is a circle
While not perfect it seemed a pretty good approximation to a quarter of a circle. I have no idea why it would be a circle. Anyway, an approximation for sigma might look like the following…
Works but I’m not that impressed
Up until this point I had been using very large samples so I decided to test things out with more realistic sample sizes and used about 10 seconds of audio consisting of some AWGN and a single sine wave; I was not impressed with the results. Sometimes the parameters were estimated quite well while other times not so good. It seems to perform worse when is very large and is small. Anyway here’s a plot of and an estimate for obtained from the previous three equations versus the frequency band for 10 seconds worth of audio using 32 ms audio blocks and sample rate of 8 kHz…
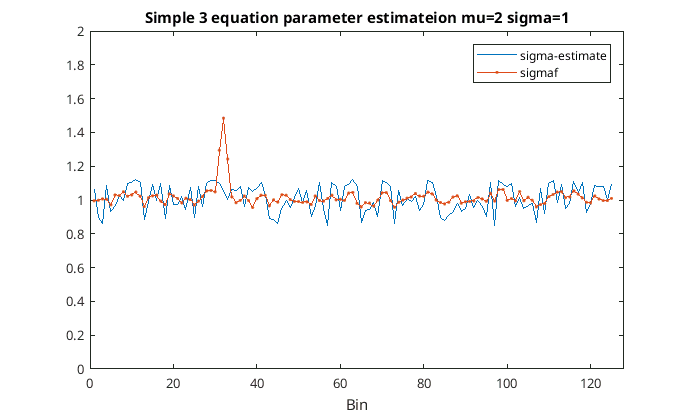 Using the three equation parameter estimation technique for sigma
Using the three equation parameter estimation technique for sigma
So in this instance the sigma estimate has pretty much ignored the interfering sine wave. However, anywhere the sine wave is not present the sigma estimate has a lot more noise and than .
It’s a Rician distribution!!!
I’m not sure why didn’t do this earlier but I took my sampled data from the output of my model and used Matlab to all the types of distributions Matlab knew about with that data to see which type of distribution would fit best. Without a shadow of a doubt the distribution Matlab called the Rician distribution was the one and fitted perfectly…
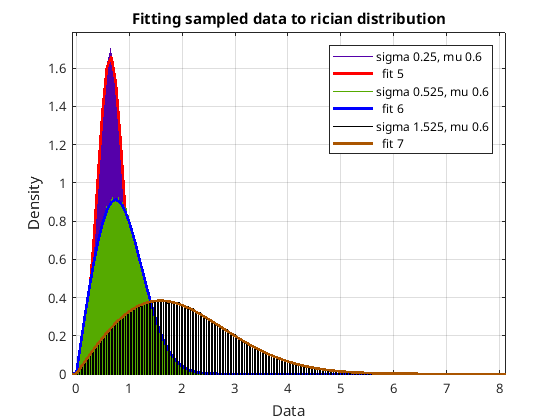 Fitting sample data to Rician distributions
Fitting sample data to Rician distributions
So it was off to Wikipedia to read up about the Rician distribution. Oh do I feel silly…
 Rice distribution motivation (Wikipedia CC)
Rice distribution motivation (Wikipedia CC)
“In the 2D plane, pick a fixed point at distance ν from the origin. Generate a distribution of 2D points centered around that point, where the x and y coordinates are chosen independently from a Gaussian distribution with standard deviation σ (blue region). If R is the distance from these points to the origin, then R has a Rice distribution.” (Wikipedia CC)
This description from Wikipedia is exactly my problem. A normal bivariate distribution with an offset, then the distance from the origin is a Rician distribution. I’m not sure I didn’t see that before. Oh well. Looking through the Wikipedia page it looks a terrible distribution to work with where there are endless funny sounding functions. However, I understand enough to estimate sigma from sigmaf and muf from that Wikipedia page. Using the notation I’ve used so far, parameter estimation goes something like this…
max_iterations=300;
r=muf/sigmaf;
theta=0;
for k=1:max_iterations
xi=(2+theta^2-(pi/8)*exp(-(theta^2)/2)*((2+theta^2)*besseli(0,(theta^2)/4)+(theta^2)*besseli(1,(theta^2)/4))^2);
sigma_estimate=sigmaf/sqrt(xi/2);
mu_estimate=sqrt(muf^2+sigmaf^2-sigma_estimate^2);
theta=sqrt(2)*mu_estimate/sigma_estimate;
end
The magic equation I was missing was the xi equation. I am not going to attempt to figure out how to drive this equation. With a bit of safety checks I tried this algorithm out…
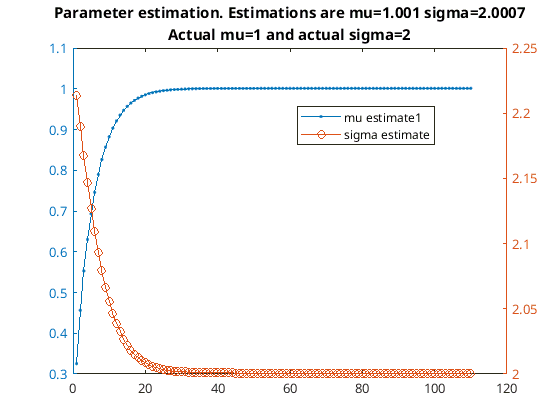 Parameter estimation
Parameter estimation
It’s slower to converge mu is small compared to sigma than if mu is large compared to sigma. Having a look at the xi function I got this…
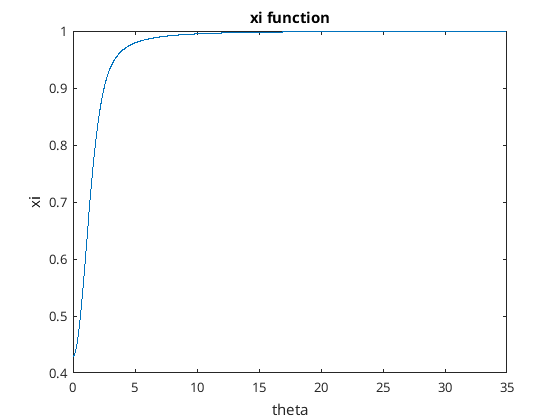 xi function
xi function
It seems to be a monotonic increase in function. I can use that fact to make an algorithm that converges quicker…
clc;
clear all;
close all;
rng(2);
mu=1;
sigma=2;
NNN=100000;
X=sigma*randn(NNN,1)/sqrt(2);
Y=sigma*randn(NNN,1)/sqrt(2);
y2=abs((X+mu)+1i*Y);
muf=mean(y2);
sigmaf=std(y2);
r=muf/sigmaf;
if r>100000000
r=100000000;
end
theta=0;
ys=[];
ys2=[];
xs=[];
step=10;
sigma_estimate_last=-1;
for k=0:1:200
%calc xi
if(theta<0)
theta=0;
end
if(theta>35)
theta=35;
end
if(isnan(theta))
theta=1;
end
xi=(2+theta^2-(pi/8)*exp(-(theta^2)/2)*((2+theta^2)*besseli(0,(theta^2)/4)+(theta^2)*besseli(1,(theta^2)/4))^2);
if ((xi*(1+r^2)-2)<0)
xi=2/(1+r^2);
end
%take a step and update theta
g=real(sqrt(xi*(1+r^2)-2));
theta=(theta+step*(g-theta));
step=step-0.25;
if theta>35
theta=35;
step=step/1.5;
end
if theta<0
theta=0;
step=step/1.5;
end
step=max(step,1);
%calc sigma_estimate and mu_estimate
sigma_estimate=sigmaf/sqrt(xi/2);
mu_estimate=real(sqrt(muf^2+sigmaf^2-sigma_estimate^2));
ys2(end+1)=sigma_estimate;
ys(end+1)=mu_estimate;
xs(end+1)=k;
if(abs((sigma_estimate_last-sigma_estimate)/sigma_estimate)<0.00000000001)
break;
end
sigma_estimate_last=sigma_estimate;
end
yyaxis left
plot(xs,ys,'.-');hold on;
yyaxis right
plot(xs,ys2,'o-');hold on;
legend({'mu estimate','sigma estimate'});
title(['Faster parameter estimation. Estimations are mu=',num2str(mu_estimate),' sigma=',num2str(sigma_estimate)]);
It’s basically the Newton-Raphson method where I haven’t bothered to calculate the derivative and instead used an adaptive step. Here is it working on the same problem as before this time it only takes 16 iterations to converge…
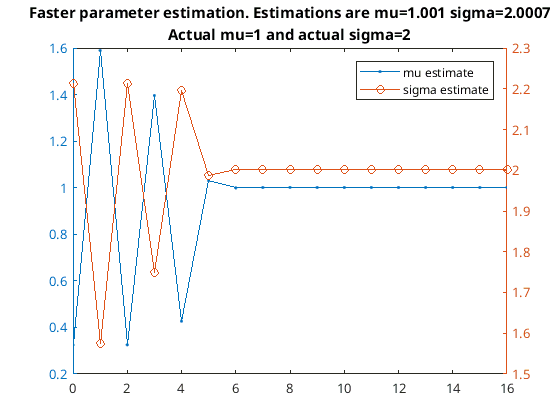 Fast parameter estimation
Fast parameter estimation
Convergence using faster convergence method
Fancy xi vs simple skewness
I wrote some code to compare the two methods of estimating the noise floor for each bin where just the 1 kHz bin had a signal and performed 100 tests of doing this. Each of the test consisted of 10 seconds of audio at 8 kHz sample rate, the Fourier transform’s consisted of 32 ms each. I got the following two figures for mu=2 and sigma=0.25…
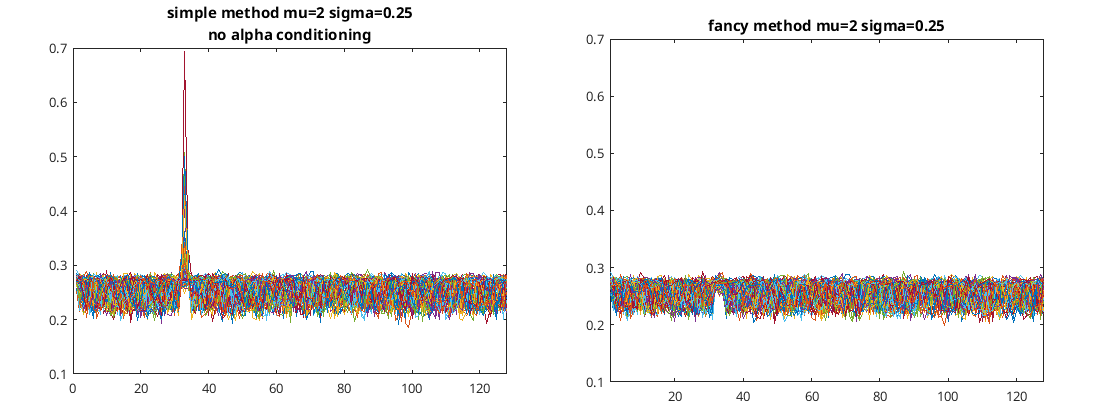 Comparing the two noise estimation algorithms: Fancy xi vs simple skewness
Comparing the two noise estimation algorithms: Fancy xi vs simple skewness
As you can see in this case the simple method (i.e. using the skewness of the distribution) does not estimate the noise floor as well is the more complicated method using the xi function. The simple method is OK when mu is small compared to sigma but gets worse when mu gets bigger. To try and improve this situation I conditioned alpha such that when it’s above a certain number I set it to one. With the same mu and sigma as before this time I got the following…
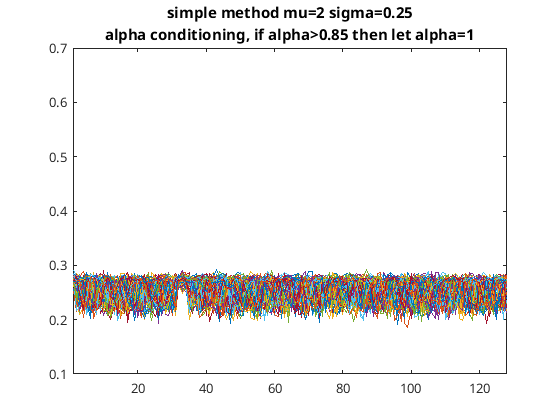 Simple method with alpha conditioning
Simple method with alpha conditioning
So that’s OK but still doesn’t beat the fancy the xi method. The following two figures compare the two methods for a lower value of mu…
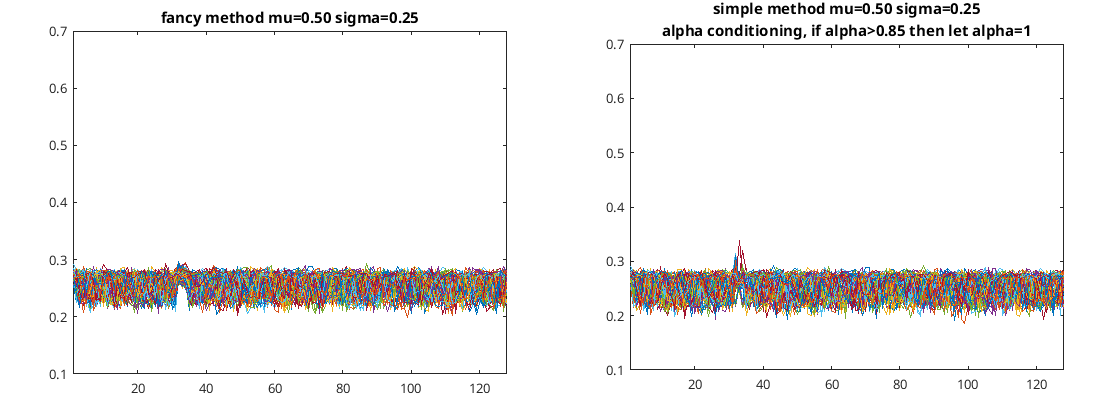 Comparing the two noise estimation algorithms with a lower mu
Comparing the two noise estimation algorithms with a lower mu
So certainly the xi algorithm is best but is trickier to implement. However there’s not that much difference between the two in the results. In both algorithms there is a bias in the bin that contains the constant signal but less standard deviation in that bin compared to the others; that sucks.
The following code is what I used to generate these figures…
clc;
clear all;
close all;
rng(1);
seconds_wanted=10;
Fs=8000;
mu=0.5;
sigma=0.25;
max_number_of_tries=100;
sigma_estimates_fast=zeros(max_number_of_tries,128);
sigma_estimates_slow=zeros(max_number_of_tries,128);
mu_estimates_fast=zeros(max_number_of_tries,128);
mu_estimates_slow=zeros(max_number_of_tries,128);
zeros(max_number_of_tries,128);
for trycount=1:max_number_of_tries
NNN=Fs*seconds_wanted;
sin_wave = 1*sin(2*pi*1000.1*[1:NNN]/Fs)';
sig_test=mu*sin_wave/128+sigma*randn(NNN,1)/18.025;
block_size=256;%-->32ms blocks
scale=mean(hann(256));
%FFTs
XBs=zeros(256,floor(numel(sig_test)/(block_size/2))+1);
m=0;
for k=1:12:numel(sig_test)-256%ffts are 50% overlapped
xb=sig_test(k:k+256-1).*hann(256);%signal is sine wave plus noise
m=m+1;
XBs(:,m)=fft(xb)./scale;
end
XBs=XBs(1:128,1:m);
%calc stats from XBs
muf=mean(abs(XBs'));%folded mean
sigmaf=std(abs(XBs'));%folded sigma
sku=(mean((abs(XBs')-muf).^3)./(sigmaf.^3))/0.6311245;%folded normalized skew
% sku=skewness(abs(XBs'))/0.6311245;%folded normalized skew (same as above)
sku(isnan(sku))=1;%in case sigmaf is zero
sku=max(min(sku,1),0);
alpha=(sqrt(1-sku.^2));%calc alpha from folded normalized skew
alpha(alpha>0.85)=1;%alpha conditioning
sigma_estimate=(sqrt(alpha.*(sigmaf.^2-muf.^2)+(sigmaf.^2+muf.^2)));%calc sigma
mu_estimate=abs(sqrt(muf.^2+sigmaf.^2-sigma_estimate.^2));%calc mu
sigma_estimates_fast(trycount,:)=sigma_estimate;
mu_estimates_fast(trycount,:)=mu_estimate;
for k=1:numel(sigmaf)
[sigma_estimate(k),mu_estimate(k)] = estimateParameters(sigmaf(k),muf(k));
end
sigma_estimates_slow(trycount,:)=sigma_estimate;
mu_estimates_slow(trycount,:)=mu_estimate;
end
plot(sigma_estimates_slow');
ylim([0.1 0.7]);
title('fancy method');
figure;
plot(sigma_estimates_fast');
ylim([0.7 0.7]);
title('simple method');
function [sigma_estimate,mu_estimate] = estimateParameters(sigmaf,muf)
r=muf/sigmaf;
if r>100000000
r=100000000;
end
theta=0;
step=10;
sigma_estimate_last=-1;
for k=0:1:200
if(theta<0)
theta=0;
end
if(theta>35)
theta=35;
end
if(isnan(theta))
theta=1;
end
xi=(2+theta^2-(pi/8)*exp(-(theta^2)/2)*((2+theta^2)*besseli(0,(theta^2)/4)+(theta^2)*besseli(1,(theta^2)/4))^2);
if ((xi*(1+r^2)-2)<0)
xi=2/(1+r^2);
end
g=real(sqrt(xi*(1+r^2)-2));
theta=(theta+step*(g-theta));
step=step-0.25;
if theta>35
theta=35;
step=step/1.5;
end
if theta<0
theta=0;
step=step/1.5;
end
step=max(step,1);
sigma_estimate=sigmaf/sqrt(xi/2);
mu_estimate=real(sqrt(muf^2+sigmaf^2-sigma_estimate^2));
if(abs((sigma_estimate_last-sigma_estimate)/sigma_estimate)<0.00000000001)
break;
end
sigma_estimate_last=sigma_estimate;
end
end
I like the xi method so let’s create an approximation of the xi function. I used Matlab’s curve fitting application to create a piecewise function that approximates xi. I decided to split the function up from numbers up to 2.5 and then from 2.5 to 35. The polynomial for the smaller numbers and a rational function for the large numbers seem to be OK. This is what the piecewise function looks like…
if(theta<2.5)
p1 = -0.003754;% (-0.003756, -0.003752)
p2 = 0.03236;% (0.03234, 0.03237)
p3 = -0.08832;% (-0.08837, -0.08827)
p4 = 0.02423;% (0.02417, 0.0243)
p5 = 0.2073;% (0.2073, 0.2074)
p6 = 0.0008758;% (0.0008628, 0.0008888)
p7 = 0.4292;% (0.4292, 0.4292)
xi_approx = p1*theta^6 + p2*theta^5 + p3*theta^4 + p4*theta^3 + p5*theta^2 + p6*theta + p7;
else
p1 = 0.9999;% (0.9999, 0.9999)
p2 = 0.3294;% (0.322, 0.3368)
p3 = -7.987;% (-8.008, -7.965)
p4 = 9.192;% (9.173, 9.211)
q1 = 0.3247;% (0.3173, 0.332)
q2 = -7.389;% (-7.41, -7.368)
q3 = 8.499;% (8.479, 8.518)
xi_approx = (p1*theta^3 + p2*theta^2 + p3*theta + p4) / (theta^3 + q1*theta^2 + q2*theta + q3);
end
The percentage error of this function looks like the following…
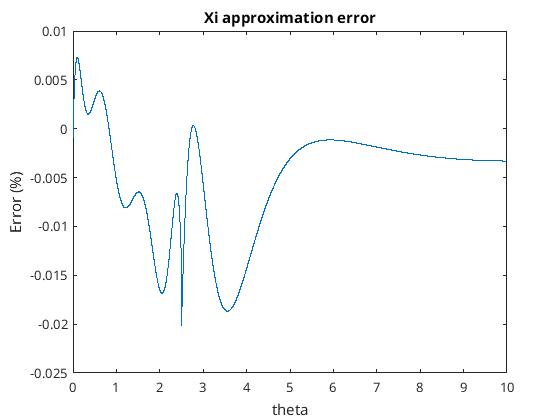 Xi approximation error using piecewise function
Xi approximation error using piecewise function
That’s not too bad and the error of this function is less than 0.02% error. For theta above 10 it gets boring and there is very little error from there on.
So that function I can put into the fancy xi algorithm…
function result = xi_approx(theta)
if(theta<2.5)
p1 = -0.003754;% (-0.003756, -0.003752)
p2 = 0.03236;% (0.03234, 0.03237)
p3 = -0.08832;% (-0.08837, -0.08827)
p4 = 0.02423;% (0.02417, 0.0243)
p5 = 0.2073;% (0.2073, 0.2074)
p6 = 0.0008758;% (0.0008628, 0.0008888)
p7 = 0.4292;% (0.4292, 0.4292)
result = p1*theta^6 + p2*theta^5 + p3*theta^4 + p4*theta^3 + p5*theta^2 + p6*theta + p7;
else
p1 = 0.9999;% (0.9999, 0.9999)
p2 = 0.3294;% (0.322, 0.3368)
p3 = -7.987;% (-8.008, -7.965)
p4 = 9.192;% (9.173, 9.211)
q1 = 0.3247;% (0.3173, 0.332)
q2 = -7.389;% (-7.41, -7.368)
q3 = 8.499;% (8.479, 8.518)
result = (p1*theta^3 + p2*theta^2 + p3*theta + p4) / (theta^3 + q1*theta^2 + q2*theta + q3);
end
end
function [sigma_estimate,mu_estimate] = estimateParameters(sigmaf,muf)
r=muf/sigmaf;
if r>100000000
r=100000000;
end
theta=0;
step=10;
sigma_estimate_last=-1;
for k=0:1:200
if(theta<0)
theta=0;
end
if(theta>35)
theta=35;
end
if(isnan(theta))
theta=1;
end
xi=xi_approx(theta);
if ((xi*(1+r^2)-2)<0)
xi=2/(1+r^2);
end
g=real(sqrt(xi*(1+r^2)-2));
theta=(theta+step*(g-theta));
step=step-0.25;
if theta>35
theta=35;
step=step/1.5;
end
if theta<0
theta=0;
step=step/1.5;
end
step=max(step,1);
sigma_estimate=sigmaf/sqrt(xi/2);
mu_estimate=real(sqrt(muf^2+sigmaf^2-sigma_estimate^2));
if(abs((sigma_estimate_last-sigma_estimate)/sigma_estimate)<0.00000000001)
break;
end
sigma_estimate_last=sigma_estimate;
end
end
And now I have something that can be put into C++, say…
class Xi_approx
{
public:
Xi_approx(){};
double evalf(double theta);
private:
double p[7]={
-0.003754,// (-0.003756, -0.003752)
0.03236,// (0.03234, 0.03237)
-0.08832,// (-0.08837, -0.08827)
0.02423,// (0.02417, 0.0243)
0.2073,// (0.2073, 0.2074)
0.0008758,// (0.0008628, 0.0008888)
0.4292// (0.4292, 0.4292)
};
double r[7]={
0.9999,// (0.9999, 0.9999)
0.3294,// (0.322, 0.3368)
-7.987,// (-8.008, -7.965)
9.192,// (9.173, 9.211)
0.3247,// (0.3173, 0.332)
-7.389,// (-7.41, -7.368)
8.499// (8.479, 8.518)
};
};
double Xi_approx::evalf(double theta)
{
double result=0;
double theta2=theta*theta;
double theta3=theta2*theta;
if(theta<2.5)
{
double theta4=theta2*theta2;
double theta5=theta4*theta;
double theta6=theta3*theta3;
result = p[0]*theta6 + p[1]*theta5 + p[2]*theta4 + p[3]*theta3 + p[4]*theta2 + p[5]*theta + p[6];
}
else
{
result = (r[0]*theta3 + r[1]*theta2 + r[2]*theta + r[3]) / (theta3 + r[4]*theta2 + r[5]*theta + r[6]);
}
return result;
}
Which then can be used with the xi algorithm for rice parameter estimation and C++…
class Rice_Parameters
{
public:
Rice_Parameters(){};
void estimate(double sigmaf,double muf);
double sigma_estimate=0;
double mu_estimate=0;
private:
Xi_approx xi_approx;
};
void Rice_Parameters::estimate(double sigmaf,double muf)
{
double muf2=muf*muf;
double sigmaf2=sigmaf*sigmaf;
double r2=muf2/sigmaf2;
double sigma_estimate2=0;
if(r2>100000000.0)r2=100000000.0;
double theta=0;
double step=10;
double sigma_estimate2_last=-1;
for(int k=0;k<200;k++)
{
if(theta<0)theta=0;
if(theta>35)theta=35;
if(std::isnan(theta))theta=1;
double xi=xi_approx.evalf(theta);
if((xi*(1.0+r2)-2.0)<0)xi=2.0/(1.0+r2);
double g=sqrt(xi*(1.0+r2)-2.0);
if(std::isnan(g))g=0;
theta=(theta+step*(g-theta));
step=step-0.25;
if(theta>35)
{
theta=35;
step=step/1.5;
}
if(theta<0)
{
theta=0;
step=step/1.5;
}
if(step<1)step=1;
sigma_estimate2=2.0*sigmaf2/xi;
if(abs((sigma_estimate2_last-sigma_estimate2)/sigma_estimate2)<0.00000001)break;
sigma_estimate2_last=sigma_estimate2;
}
sigma_estimate=sqrt(sigma_estimate2);
mu_estimate=(sqrt(muf2+sigmaf2-sigma_estimate2));
if(std::isnan(mu_estimate))mu_estimate=0;
}
What about voice?
So far I have assumed a constant sine wave signal superimposed on the noise. This produced a Rice distribution which allowed me to calculate the amplitude of the sine wave as well as the background additive white Gaussian noise. That’s not voice though. So I created a pulsating sine wave to simulate voice…
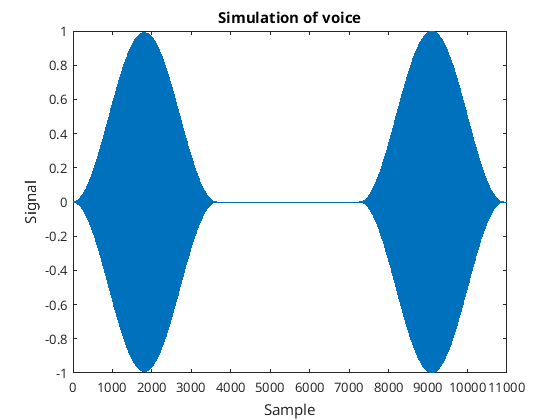 Simulated voice signal
Simulated voice signal
Assuming Rician distribution I got the following estimates for sigma…
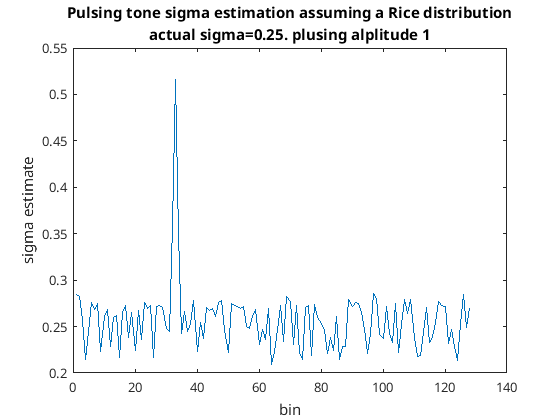 Sigma estimate for simulated voice
Sigma estimate for simulated voice
With this simulated voice the sigma estimate has totally failed for that bin; bother. This is clearly failing because mu is not constant as I assumed it to be.
So my next idea was/is to evaluate muf and sigmaf over a short period of time, say a second. As voice is something that doesn’t produce continuous sine waves there should be periods of time where the bin is not excited by any voice. When this happens we should be dealing with only a constant sine wave and additive white Gaussian noise and hence should be able to get an estimate for sigma. So the question is how do I find periods of time without any voice for each bin? For that I thought of using a larger window say 10 seconds and take the minimum muf in that window. Once the minimum is found in that window I take the corresponding sigmaf. This can be explained with the following code where XBs is an n by m matrix where n is the number of frequency bins and m are the time steps, the contents of this matrix is the absolute value from the FFTs…
Zstd=movstd(XBs',62);%1sec
Zmean=movmean(XBs',62);%1sec
Zmin_std=Zstd;
Zmin_mean=Zmean;
for k=1:size(Zmean,1)-625 %10secs
for n=1:size(Zmean,2)
[~,idx]=min(Zmean(k:k+625-1,n));
Zmin_mean(k,n)=Zmean(idx+k-1,n);
Zmin_std(k,n)=Zstd(idx+k-1,n);
end
end
Zmin_mean=Zmin_mean(1:end-625,:);
Zmin_std=Zmin_std(1:end-625,:);
Zmin_mean and Zmin_std should be for additive white Gaussian noise plus any constant signals so should be the stats of a Rice distribution which we already know how to obtain parameter estimates for this distribution. If we assume the signal does not contain any constant signals then we know in estimate for the underlying sigma is , this can be written as follows…
sigma_estimate_assuming_no_constant_signals=1.062*(sqrt(mean(Zmin_std).^2+mean(Zmin_mean).^2));
I have scaled it a bit here as I was getting a slight bias. I assume this was from the way I formed Zmin_std and Zmin_mean.
I then created a signal that contained a pulsating 1 kHz signal as well as a constant 2 kHz signal along with some additive white Gaussian noise. Sigma was 0.25 and mu was 1 for both the 1 kHz and 2 kHz signals. The pulsating rate of the 1 kHz signal was about two seconds. I created 30 seconds in total. The spectrum of 10 seconds of the signal can be seen in the following figure…
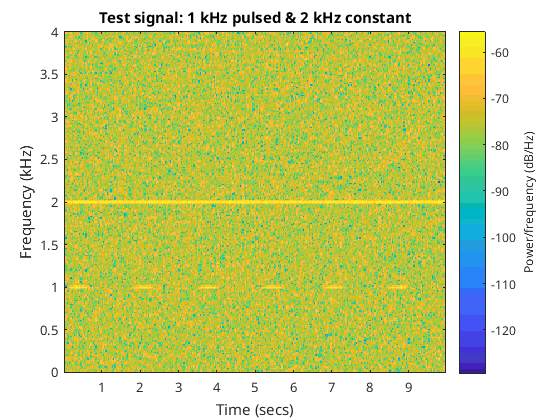 Spectrogram of the created signal
Spectrogram of the created signal
I ran the signal into the proposed dual sliding window thing I just mentioned and compared that to the previous method where I didn’t assume that there were any modulated signals. The code for this can be seen in the following code snippet given sigma_estimate_assuming_no_constant_signals…
plot(sigma_estimate_assuming_no_constant_signals);
muf=mean(XBs');%folded mean
sigmaf=std(XBs');%folded sigma
sigma_estimate=sigmaf;
mu_estimate=muf;
for k=1:numel(sigmaf)
[sigma_estimate(k),mu_estimate(k)] = estimateParameters(sigmaf(k),muf(k));
end
hold on;
plot(sigma_estimate*0.9259259);
xlim([1 256])
ylim([0.1 .55])
title({'Estimated sigma with pulsing 1kHz and constant 2kHz sine waves'});
hold off;
legend('assuming no constant signals','assuming no modulated signals');
figure;
The plot of this can be seen in the following figure…
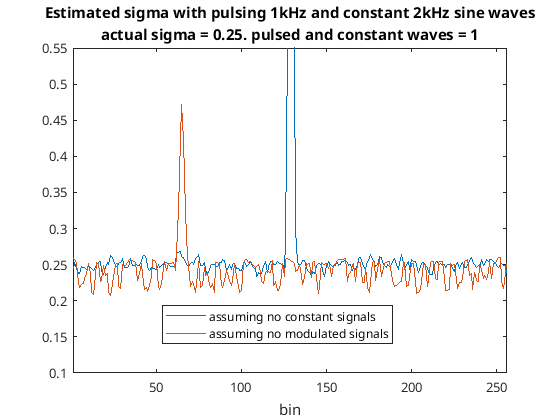 Comparing both assumptions
Comparing both assumptions
As can be seen one method ignores the pulsating signal while the other method ignores the constant signal. I am writing this as I’m going along so I don’t know for certain yet but I think the method of assuming no constant signals might be very useful even though it doesn’t estimate the noise floor if there are constant signals present. Anyway, before looking into that as Zmin_mean and Zmin_std are statistics for a signal that does not contain any modulated signals I should be able to obtain an estimate for sigma is independent of both constant and modulated signals…
muf=mean(Zmin_mean);%folded mean
sigmaf=mean(Zmin_std);%folded sigma
sigma_estimate=sigmaf;
mu_estimate=muf;
for k=1:numel(sigmaf)
[sigma_estimate(k),mu_estimate(k)] = estimateParameters(sigmaf(k),muf(k));
end
plot(sigma_estimate*1.066098081);
title('Estimated sigma with pulsing 1kHz and constant 2kHz sine waves');
ylim([0.1 .55])
xlim([1 256])
legend('neither assumptions');
Again I have scaled sigma_estimate ever so slightly. This produces the following plot…
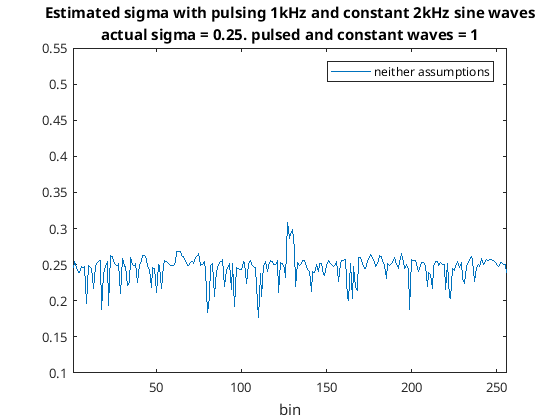 Making neither assumption
Making neither assumption
So you can see this time neither a great 1 kHz or 2 kHz signal appears. However there is still a slight peak around 2 kHz and there’s a lot more standard deviation than when I made the assumption that there were no constant signals. Anyway this seems promising for a way to estimate the noise floor in the presence of constant and modulated signals such as voice. So let’s try a real life example with voice and I’ll add a constant signal to that and see what happens.
Real life voice tests
For the first voice test I used a two minute signal Darren sent me of a weak HF signal. The signal sounded like it was some sort of continuously repeating weather report. The signal was so weak I could only make out bits and pieces of what was being said. I added a constant sine wave at 2 kHz and ran it through the code…
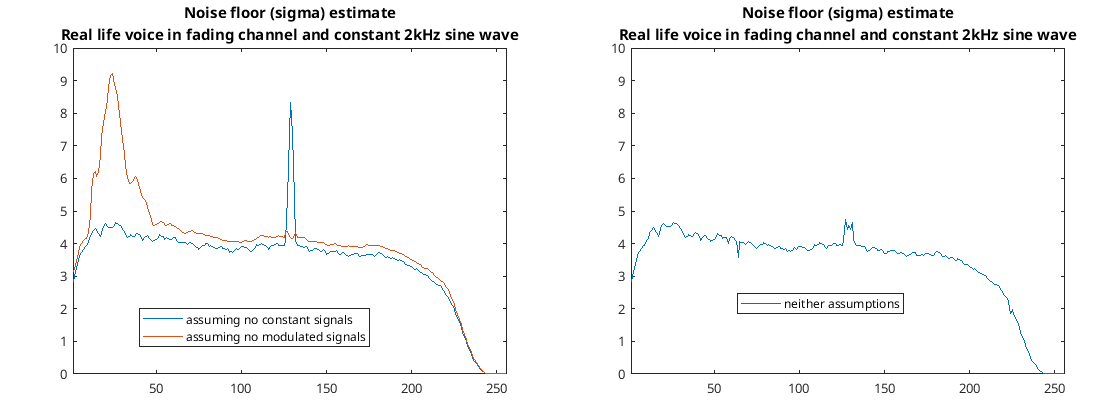 Real life results from the weak weather report signal with added 2 kHz sine wave
Real life results from the weak weather report signal with added 2 kHz sine wave
The results from this test look quite good and it looks like it is estimated noise floor quite well.
I then created my own signal using my own voice added some white noise, a 2 kHz sine wave, and adjusted the response such that about half of the spectrum was linearly sloping down while the other half was flat…
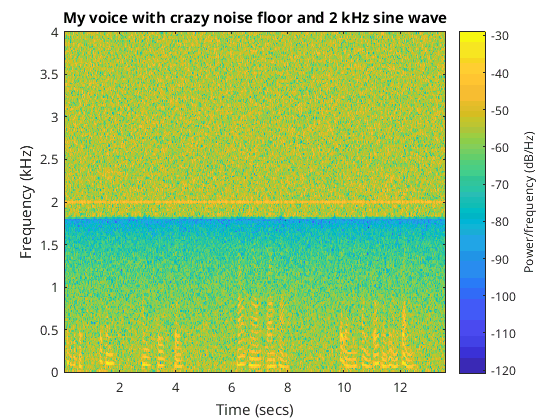 Spectrogram of my crazy signal
Spectrogram of my crazy signal
This time the code produced the following graphs…
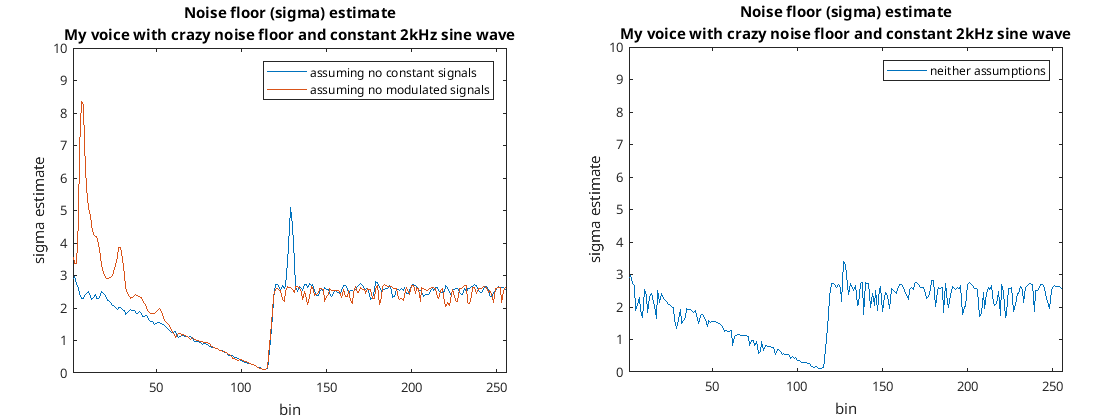 Results from my crazy signal
Results from my crazy signal
Again it seems to have worked fine and estimated noise floor reasonably well considering.
Whitening
When the input to a complex FFT is real you can get rid of about half of due to the conjugate symmetry without any loss of information. A 512 point complex FFT with real input can go to a 257 complex output. You can also pad the input signal with zeros to increase the number of frequency bins. For the FFT I decided to pad the input signal to the FFT and use a 512 point complex FFT with 257 complex bins at the output; the FFTs became the following…
%FFTs
XBs=zeros(256+1,floor(numel(sig_test)/(block_size/2))+1);
m=0;
for k=1:128:numel(sig_test)-256%ffts are 50% overlapped
xb=sig_test(k:k+256-1).*hann(256);
xb=[xb;zeros(numel(xb),1)];
m=m+1;
XB=fft(xb)./scale;
XBs(:,m)=XB(1:numel(XB)/2+1);
end
I can reconstitute signal using an overlap and add method like the following…
%reconstitute signal.
x=[];
xb_last=zeros(256,1);
for k=1:size(XBs,2)
XB=XBs(:,k);
XB=[XB;conj(flip(XB(2:end-1)))];
xb=real(ifft(XB));
xb=xb(1:numel(xb)/2);
xbc=0.5*(xb(1:128)+xb_last(129:256));
x=[x;xbc];
xb_last=xb;
end
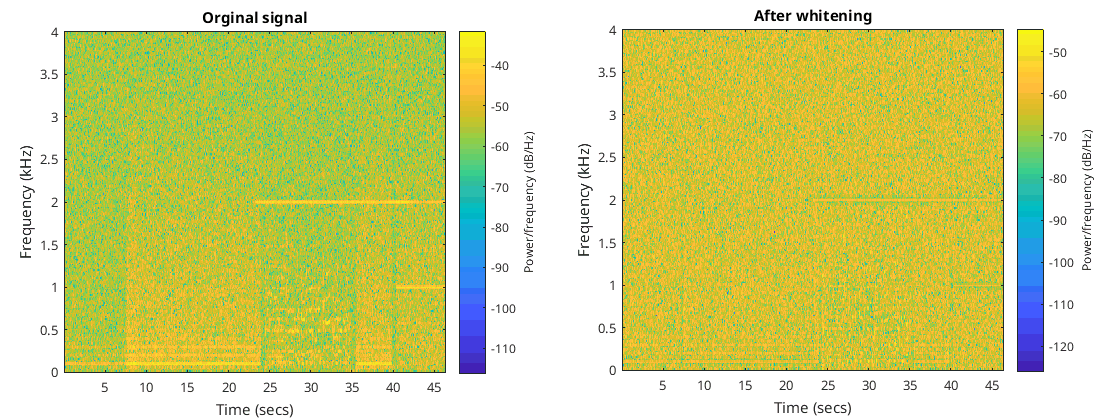
I then got rid of the voice and the constant sine wave 2 kHz and just retained the crazy noise as input. I wished to flatten or whiten this input signal and normalize it such that its segment was one. This is easy enough and just means dividing each bin by a sigma estimate then reconstituting the signal again. I decided to use the sigma estimate assuming no constant signals. The code then becomes…
%reconstitute signal. normalize std assuming no constant signals
x=[];
xb_last=zeros(256,1);
for k=1:size(XBs,2)
XB=XBs(:,k);
XB=XB./sigma_estimate_assuming_no_constant_signals';
XBs(:,k)=XB;
XB=[XB;conj(flip(XB(2:end-1)))];
xb=real(ifft(XB));
xb=xb(1:numel(xb)/2);
xbc=0.5*(xb(1:128)+xb_last(129:256));
x=[x;xbc];
xb_last=xb;
end
With this I got the following graphs…
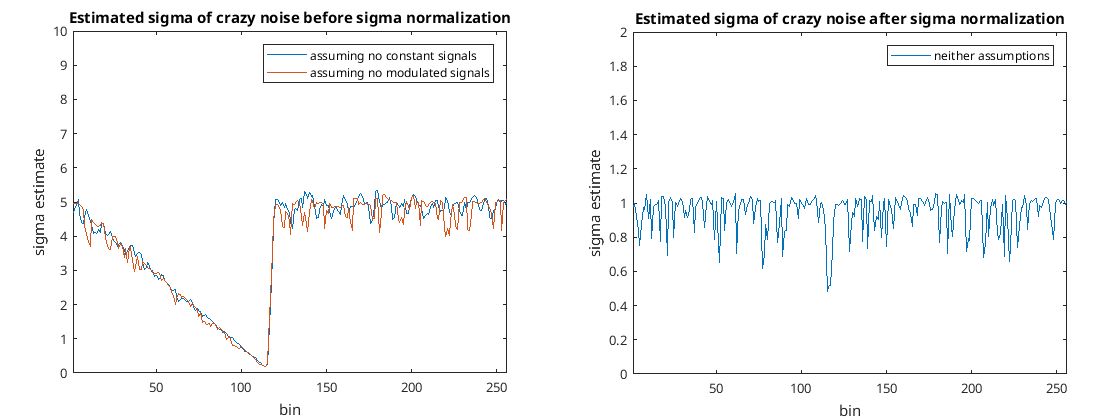
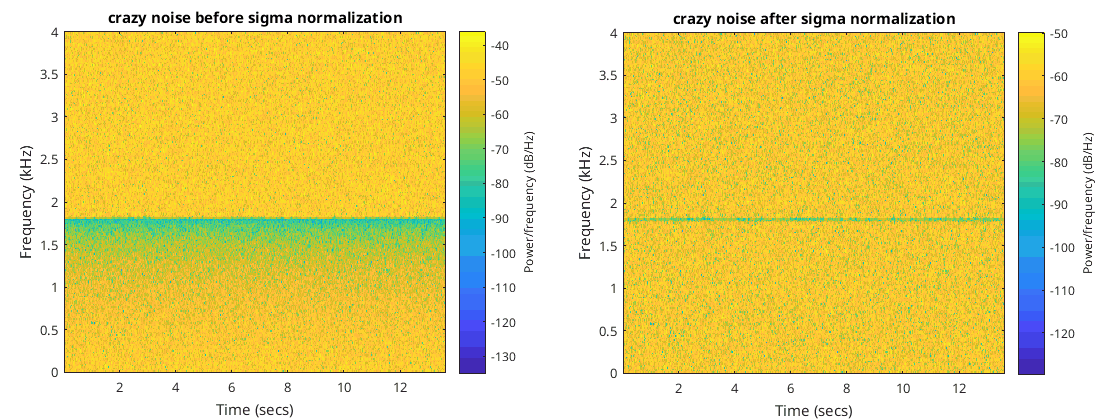
You can see indeed it does normalize the standard deviation and whiten the signal. There is a little glitch due to the nonlinearity in the frequency domain but that’s never going to happen in real life.
The nice thing about whitening is that the random variable from each bin consisting of the absolute value always comes from a distribution that has a standard deviation of one meaning it’s one less thing we have to figure out.
This method of whitening doesn’t work for constant sine waves but instead will reduce the volume for that bin more than it should. I think this will be fine, in fact I think it’s something I want as in the end I effectively want to ignore constant sine waves as they are most likely interference. You can see this in the following figures where I have applied this method of whitening to the crazy noise signal in addition to the 2 kHz constant sine wave and the talking…
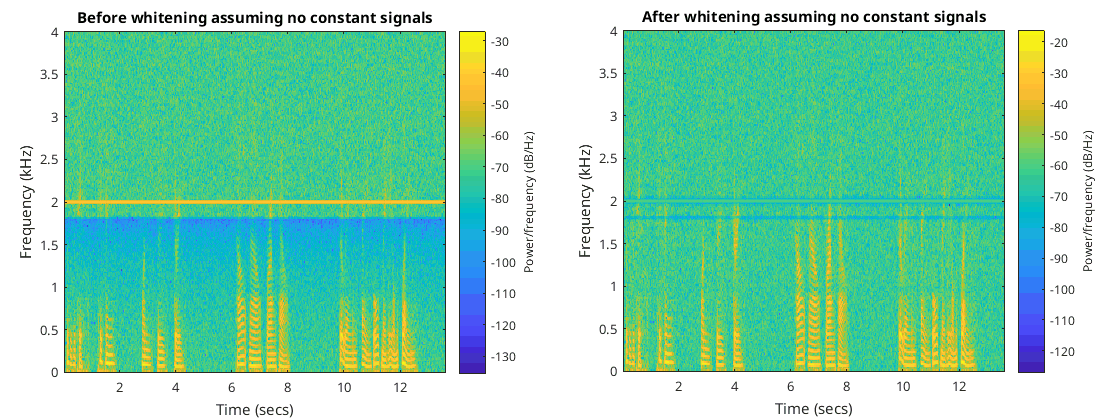
As can be seen the constant 2 kHz sine wave becomes less prominent than the talking.
SNR
We know that . We can write this in some sort of signal-to-noise ratio (SNR) . Doing the whitening we have an estimate for of 1, so this SNR can be written as . There is a bit of a problem estimating and as they change all the time yet we need time to estimate them as more than one sample is needed. So I just used small windows to estimate these two values. Each bin will have its own SNR estimate but I want some sort of measure of how likely voice exists in the signal, so I think looking for the bin that has the greatest SNR should be a good estimate of this. Doing this of course is going to cause some sort of bias and make the SNR seem larger than it should when voice is not present. Because of this I chose my estimate of sigma to be greater than one so as to bring down the SNR. The following code seem to work quite well to estimate the voice SNR…
ZstdFast=movstd(abs(XBs'),31);%0.5sec
ZmeanFast=movmean(abs(XBs'),31);%0.5sec
snr_estimate=[];
for k=10:size(ZmeanFast,1)
r=max((ZmeanFast(k,:).^2+ZstdFast(k,:).^2-2),0)/2;%2 as seems to estimate mu too large
snr_estimate(end+1)=max(r(4:96));%only bother about frequencies where most voice energy is
end
snr_estimate=movmean(snr_estimate,62);%1 sec smoothing
plot(linspace(0,numel(snr_estimate)*128/Fs,numel(snr_estimate)),10*log10(snr_estimate));
ylim([-10 20]);
ylabel('SNR (dB)');
xlabel('time (s)');
title('Voice signal to noise estimate');
I added yet more additive white Gaussian noise to the input signal than was done in the whitening section of this document. This signal I put into the previous code. The output to this code as well as the associated spectrum can be seen in the following figures…
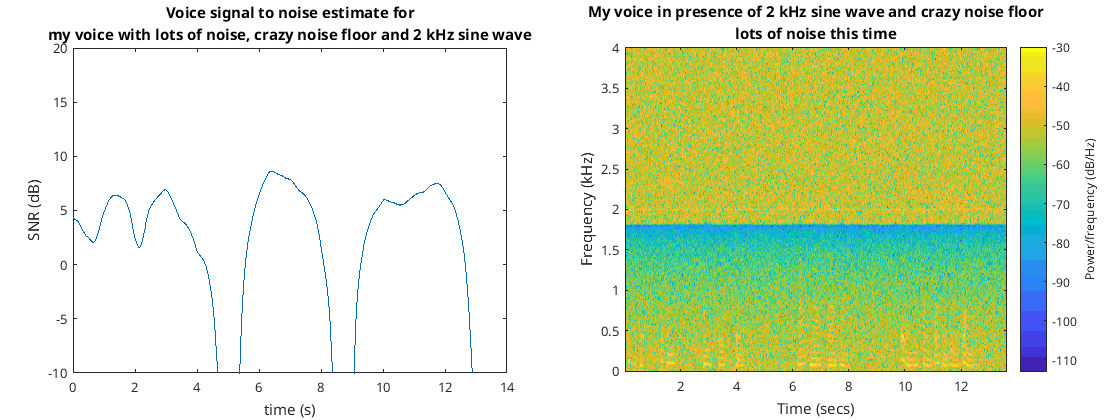
That worked quite well and shows that periods of time when I wasn’t speaking.
I then tried this out with the terrible weather signal of the lady talking, she doesn’t exactly stop talking but the fades are so bad that the intelligibility is all over the show…
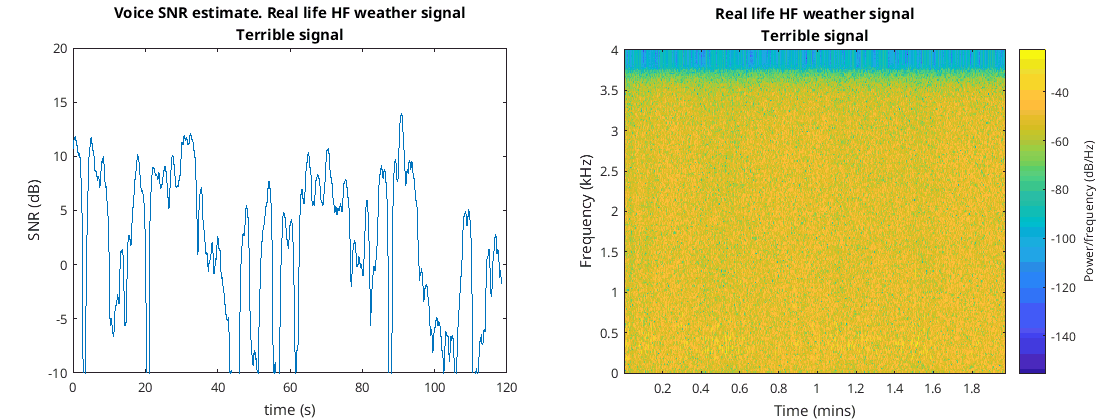
I did think about estimating this SNR using the formula of the mean of the Rice distribution () when sigma is equal to 1 and using just one sample to estimate the mean. This didn’t work too well and it also meant finding the inverse of the mean function which as far as I could figure out didn’t have any nice way of writing it and needs another iterative algorithm to solve it as well as it’s easier to estimate and and just use the method I just demonstrated.
Signal decision and final reconstitution
I had another signal that I obtaind by making a recording on a radio tuning the frequency to different stations as well as adjusting the volume. I realized with this test signal that my whitening code assume the noise floor to be constant over the entire recording which of course in this case it wasn’t. I changed it so that the noise estimation would be over a window…
%double moving windows
Zstd=movstd(abs(XBs'),short_moving_window_size);
Zmean=movmean(abs(XBs'),short_moving_window_size);
Zmin_std=Zstd;
Zmin_mean=Zmean;
for k=1:size(Zmean,1)
for n=1:size(Zmean,2)
[~,idx]=min(Zmean(k:min(k+long_moving_window_size-1,size(Zmean,1)),n));
Zmin_mean(k,n)=Zmean(idx+k-1,n);
Zmin_std(k,n)=Zstd(idx+k-1,n);
end
end
%calculate normalizing factor over a window
%the bigger this window is the less agile the noise estimateion will be
moving_sigma_estimate=1.062*(sqrt((Zmin_std).^2+(Zmin_mean).^2));
moving_sigma_estimate=movmean(moving_sigma_estimate,62);
And flattening became…
%normalize std assuming no constant signals. this
%produces a flat noise floor of about 1
for k=1:size(XBs,2)
XB=XBs(:,k);
XB=XB./moving_sigma_estimate(k,:)';
XBs(:,k)=XB;
end
I also wanted and SNR estimate for each bin as well as the maximum voice SNR as previously described. I also didn’t really care that the new estimate was a bit too big so I got rid of the 2 I previously mentioned. So the SNR estimate became…
%produce lin_snrs a moving snr estimate of the speech
%snr_estimate is just for plotting and signal decision
ZstdFast=movstd(abs(XBs'),8);%needs to be small
ZmeanFast=movmean(abs(XBs'),8);%needs to be small
snr_estimate=[];
lin_snrs=XBs;
for k=1:size(ZmeanFast,1)
mu=max((ZmeanFast(k,:).^2+ZstdFast(k,:).^2-1),0)/1;%mu estimate
lin_snrs(:,k)=mu';
snr_estimate(end+1)=max(mu(4:96));%only bother about frequencies where most voice energy is
end
lin_snrs=movmean(lin_snrs',8);%reduces white noise but makes it sound echoy and strange
snr_estimate=movmean(snr_estimate,62);%1 sec smoothing
snr_estimate_db=10*log10(snr_estimate);
I then wished to reconstruct the signal only when snr_estimate_db was above a certain value. At the same time I thought it would be interesting to use the whitened signal and multiply this by the SNR estimate. I thought this might be a good way of reducing noise. The reconstitution code went like this…
%reconstitute signal. remove blocks that have low SNR and scale bins by
%their snr estimate
min_snr_required_in_dB=5;
x=[];
xb_last=zeros(256,1);
for k=1:size(XBs,2)
if(snr_estimate_db(k)<min_snr_required_in_dB)
continue;
end
XB=XBs(:,k).*(lin_snrs(k,:)');
% XB=XBs(:,k);
XB=[XB;conj(flip(XB(2:end-1)))];
xb=real(ifft(XB));
xb=xb(1:numel(xb)/2);
xbc=0.5*(xb(1:128)+xb_last(129:256));
x=[x;xbc];
xb_last=xb;
end
x(1:Fs)=[];
x=x./(max(max(x),-min(x)));
Now x contains the final signal without any of the time periods of the original signal where no voice was as well as attempting to reduce the noise to make the desired voice signal sound more prominent. I tried this out on the recording I mentioned before and got the following spectrograms for before and after the whitening…
 Before and after whitening
Before and after whitening
There is only voice between about 25 and 35 seconds the rest of it is just noise. You can see some constant interference signals as well as a 2 kHz interference signal produced by myself. I added extra white noise to the original signal as well.
As you can see the whitened signal looks fairly homogenous in comparison to the original signal which is what whitening does.
The following figures show the maximum voice signal to noise ratio which is used for deciding whether or not to keep that part of the recording as well as the reconstituted signal technique just described…
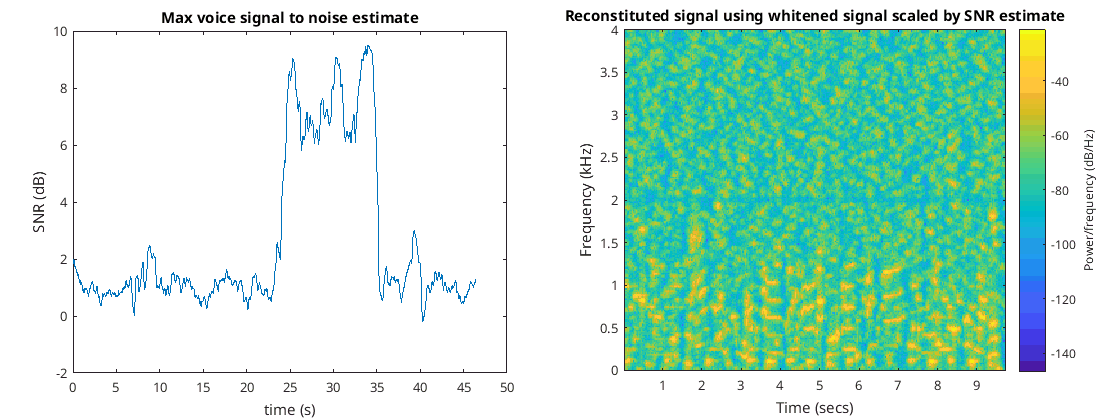 SNR estimate and reconstituted audio with snr scaling
SNR estimate and reconstituted audio with snr scaling
With a minimum SNR of five it is detected that there is a signal between about 25 and 35 seconds. The reconstituted signal is missing the 2 kHz interference and is fairly clear that there is voice in the signal. Below is the initial recording as well as the final reconstituted signal…
So I think this works reasonably well and might be a viable method of voice detection in the presence of constant interference as well as white Gaussian noise.
Product development overview
We now have an idea for an algorithm that might work to detect voice in our particular case of noise. From initial inspection I’m pretty happy with what the algorithm can do. It meets my requirements that it’s not bothered by constant sine waves, it’s not bothered by the noise floor being non-flat, it’s not bothered with the noise floor changing slowly over time, and it seems reasonably sensitive. So the next task is to make the algorithm more explicit and place it in the proper language like C++. Matlab is great for experimenting and rapidly trying out ideas but at some point you have to turn what you learn from that environment into a more explicit language. For me but C++ with Qt. I think C++ is a great language as it can be as simple or as complicated as you want it. Qt I use even for non-GUI programs and is a collection of libraries as well as a preprocessor to make tasks easier. I don’t think it’s any more difficult than Python. With Python you would type something like “pip install numpy” and then you can use numpy in Python. With C++ you would type something like “apt get install qt5-default” so you could use Qt in C++. I am also going to use qmake which is my favorite build tool. qmake makes makefiles for make and has to be the easiest one around.
I will use github for my version control. I’ll try out github’s “actions” which can be used to automate unit testing (testing that the source code sort of works) as well as building and packaging. For unit testing I might as well try cpputest then get github actions to run these tests. Then I can get one of those nice badges from github that you see around that say things like “passing”.
Initial product Requirements
The product requirements will change over time but initially I want to keep them simple.
Requirements:
- GUI
- audio input and output via soundcard driver
- voice detection algorithm as described
- user can change most settings of the voice detection algorithm
- persistent settings
- LED signifying voice present
- audio output to soundcard only happens when voice is present
- audio can be saved to disk
Architecture:
Not that sure what software architecture really is but let’s just draw a pretty graph connecting the bits and pieces required…
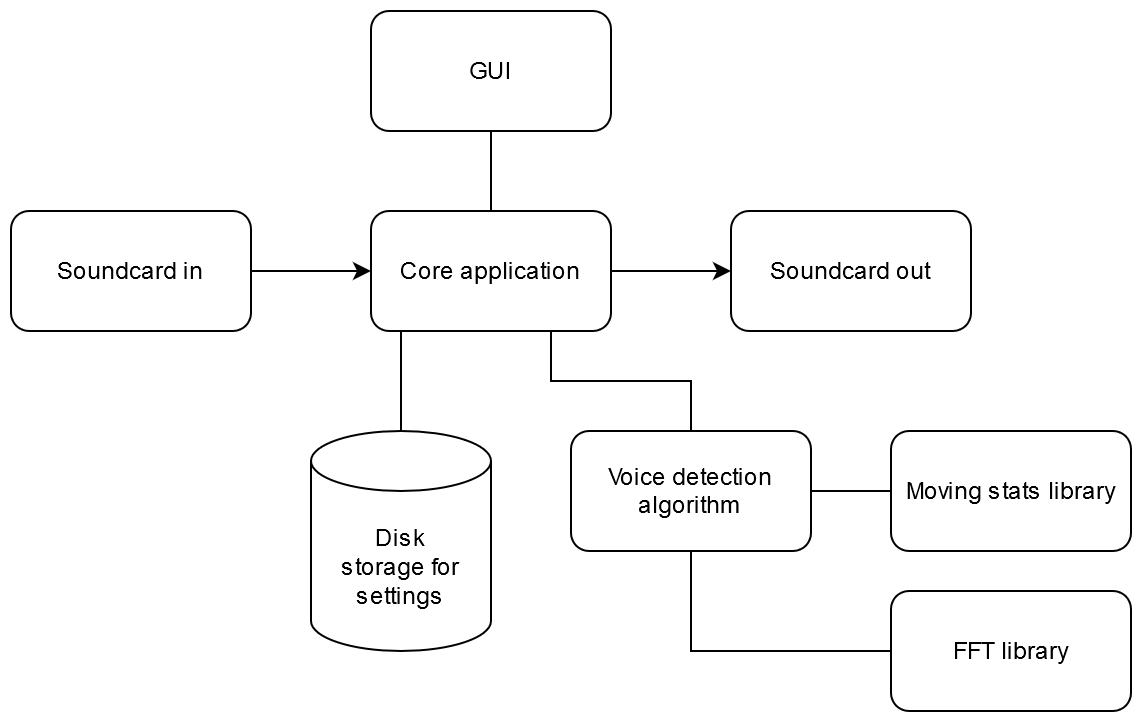 Architecture?
Architecture?
Voice detection algorithm
In Matlab the algorithm looks something like the following…
clc;
clear all;
close all;
rng(1);
mu=4*4;
sigma=0.25*9/0.6;
filename='/home/jontio/ds/3TBusb/linux_downloads/ai_hiss/untitled.wav';
sig_test= resample(audioread(filename),80,441);
Fs=8000;
sin_wave3 = 1*sin(2*pi*2000.1*[1:numel(sig_test)]/Fs)';
sin_wave3(1:floor(end/2))=0;
sig_test=1*mu*sin_wave3/128+1*sig_test+1*sigma*randn(numel(sig_test),1)/18.025;
sig_test=sig_test./(max(max(sig_test),-min(sig_test)));
audiowrite('test1_in.wav',sig_test,Fs);
spectrogram(sig_test,512,250,[],8000,'yaxis');
block_size=256;%-->32ms blocks
scale=mean(hann(256));
%FFTs
XBs=zeros(256+1,floor(numel(sig_test)/(block_size/2))+1);
m=0;
for k=1:128:numel(sig_test)-256%ffts are 50% overlapped
xb=sig_test(k:k+256-1).*hann(256);
xb=[xb;zeros(numel(xb),1)];
m=m+1;
XB=fft(xb)./scale;
XBs(:,m)=XB(1:numel(XB)/2+1);
end
XBs_org=XBs;
short_moving_window_size=16;
long_moving_window_size=8*2;
%double moving windows
Zstd=movstd(abs(XBs'),short_moving_window_size);
Zmean=movmean(abs(XBs'),short_moving_window_size);
Zmin_std=Zstd;
Zmin_mean=Zmean;
for k=1:size(Zmean,1)
for n=1:size(Zmean,2)
[~,idx]=min(Zmean(k:min(k+long_moving_window_size-1,size(Zmean,1)),n));
Zmin_mean(k,n)=Zmean(idx+k-1,n);
Zmin_std(k,n)=Zstd(idx+k-1,n);
end
end
%calculate normalizing factor over a window
%the bigger this window is the less agile the noise estimateion will be
moving_sigma_estimate=1.062*(sqrt((Zmin_std).^2+(Zmin_mean).^2));
moving_sigma_estimate=movmean(moving_sigma_estimate,62);
figure;
plot(moving_sigma_estimate)
%normalize std assuming no constant signals. this
%produces a flat noise floor of about 1
%reconstitution is only need for spectrogram below, not needed for
%production
x=[];
xb_last=zeros(256,1);
for k=1:size(XBs,2)
XB=XBs(:,k);
XB=XB./moving_sigma_estimate(k,:)';
XBs(:,k)=XB;
XB=[XB;conj(flip(XB(2:end-1)))];
xb=real(ifft(XB));
xb=xb(1:numel(xb)/2);
xbc=0.5*(xb(1:128)+xb_last(129:256));
x=[x;xbc];
xb_last=xb;
end
figure
spectrogram(x,512,250,[],8000,'yaxis');
%produce lin_snrs a moving snr estimate of the speech
%snr_estimate is just for plotting and signal decision
ZstdFast=movstd(abs(XBs'),8);%needs to be small
ZmeanFast=movmean(abs(XBs'),8);%needs to be small
snr_estimate=[];
lin_snrs=XBs;
for k=1:size(ZmeanFast,1)
mu=max((ZmeanFast(k,:).^2+ZstdFast(k,:).^2-1),0)/1;%mu estimate
lin_snrs(:,k)=mu';
snr_estimate(end+1)=max(mu(4:96));%only bother about frequencies where most voice energy is
end
lin_snrs=movmean(lin_snrs',8);%reduces white noise but makes it sound echoy and strange
snr_estimate=movmean(snr_estimate,62);%1 sec smoothing
snr_estimate_db=10*log10(snr_estimate);
%plotting max snr estimate
figure;
plot(linspace(0,numel(snr_estimate)*128/Fs,numel(snr_estimate)),snr_estimate_db);
% ylim([-10 20]);
ylabel('SNR (dB)');
xlabel('time (s)');
title('Voice signal to noise estimate');
%reconstitute signal. remove blocks that have low SNR and scale bins by
%their snr estimate
min_snr_required_in_dB=5;
x=[];
xb_last=zeros(256,1);
for k=1:size(XBs,2)
if(snr_estimate_db(k)<min_snr_required_in_dB)
continue;
end
XB=XBs(:,k).*(lin_snrs(k,:)');
XB=[XB;conj(flip(XB(2:end-1)))];
xb=real(ifft(XB));
xb=xb(1:numel(xb)/2);
xbc=0.5*(xb(1:128)+xb_last(129:256));
x=[x;xbc];
xb_last=xb;
end
x(1:Fs)=[];
x=x./(max(max(x),-min(x)));
%show what the final spectrum looks like
figure
spectrogram(x,512,250,[],8000,'yaxis');
%listen to the final signal
sound(x,Fs)
audiowrite('test1_out.wav',x,Fs);
It’s nice to have this in some sort of block diagram for reference so one has a more abstract view of the process.
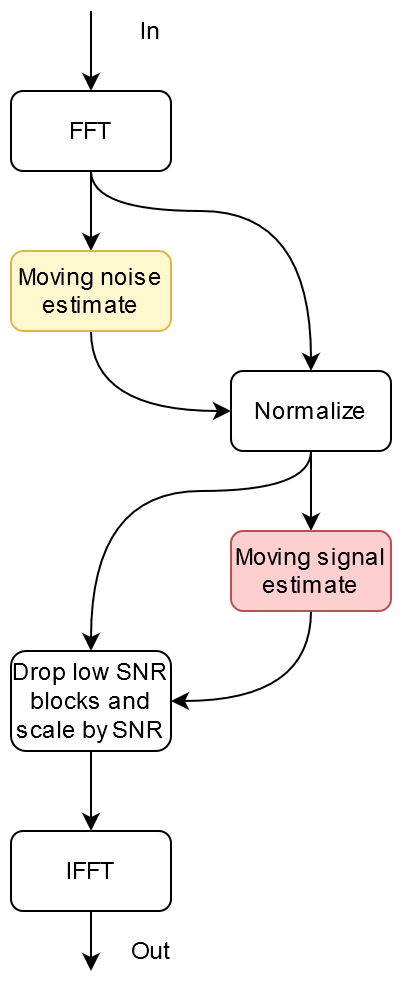 Main algo block diagram
Main algo block diagram
In a little more detail maybe…
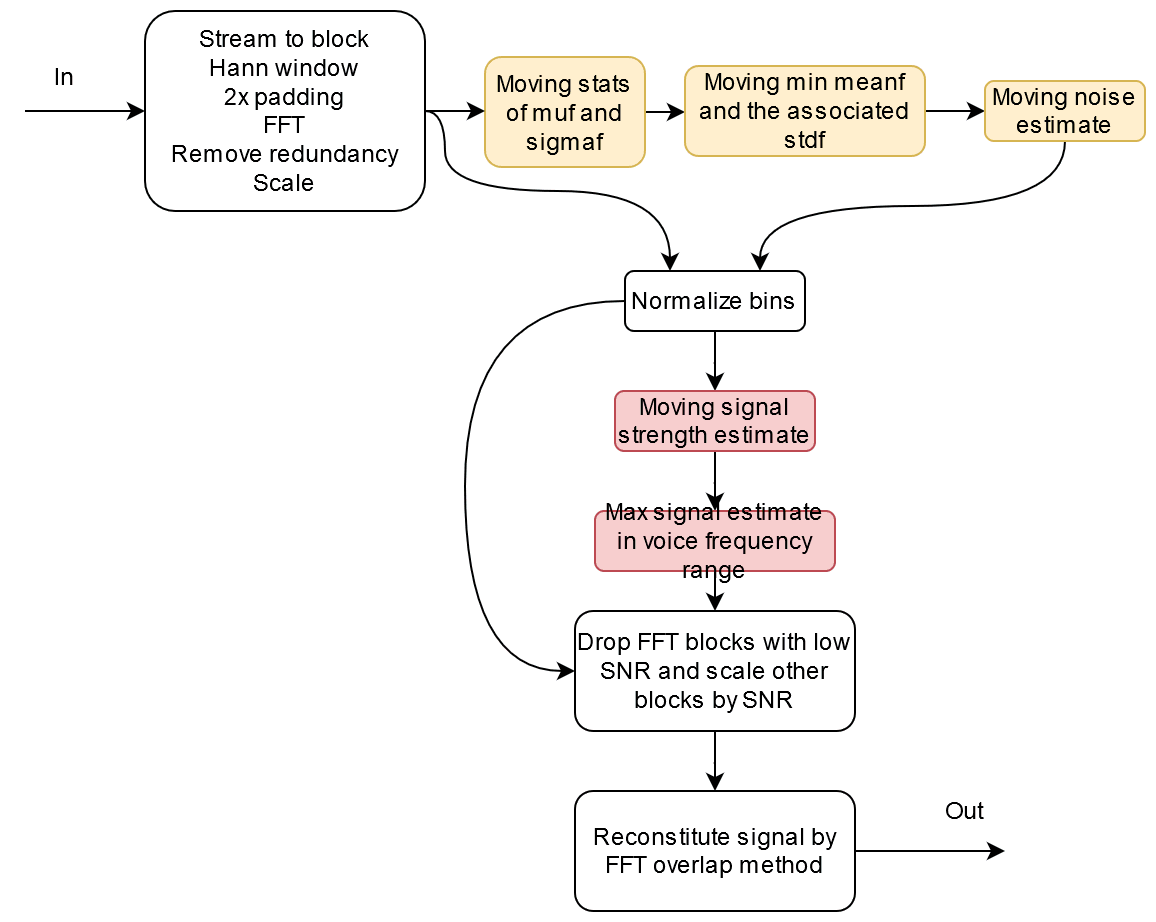 Main algo block diagram in more detail
Main algo block diagram in more detail
So we need an FFT library which I will use JFFT, and a library that does various kinds of moving statistics which I will make myself.
Moving average unit testing example
I started by creating a simple moving average filter class and produced various tests to find bugs and qualify that it would be fit for purpose. To test the class I used the CppUTest framework. This consists of writing a file with little tests in them like…
TEST(Test_DSP_MovingAverage, CreateDouble)
{
//create 3 ways
JDsp::MovingAverage<double> ma=JDsp::MovingAverage<double>(1);
LONGS_EQUAL(1,ma.getSize());
JDsp::MovingAverage<double> mb;
LONGS_EQUAL(0,mb.getSize());
JDsp::MovingAverage<double> mc(ma);
LONGS_EQUAL(1,mc.getSize());
}
In the end there are about 400 lines of test code to test about 100 lines of source code.
I uploaded this moving average filter along with the testing code to github which you can find at this commit here https://github.com/jontio/JSquelch/tree/623e950c787cfceedc6b0979d7fcec0503ffa8c1
To select between production code and test code I used the qmake pro file to change the compiled files as needed using its config option.
CI {
SOURCES += \
tests/testall.cpp \
tests/dsp_movingaverage_tests.cpp
LIBS += -lCppUTest
} else {
SOURCES += \
src/main.cpp\
}
While I ran all these tests on my own computer I was interested in getting github to do it for me. So for that I created a file in “JSquelch/.github/workflows/”. Files in this directory use a markup language called yaml which github will read and automate things for you. My file I created was called “ci.yml” and looked like the following…
name: CI
# Controls when the action will run.
on:
# Triggers the workflow on push event but only for the main branch
#push:
# branches: [ main ]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- uses: actions/checkout@v2
# Runs a single command using the runners shell
- name: Setup dependencies
run: |
sudo apt-get install qt5-default cpputest
# Runs a set of commands using the runners shell
- name: Run unit tests
run: |
qmake CONFIG+=CI
make
./jsquelch -v
echo finished testing.
# Build application
- name: Build application
run: |
make clean
qmake CONFIG-=CI
make
echo finished build.
# upload artifact
- name: Upload build
uses: actions/upload-artifact@v2
with:
name: build.zip
path: |
jsquelch
This script thing tells github to test and build my application when I tell it to do so by clicking a button. It also tells github to save the built application.
In the action tab I clicked run workflow…
 CI in GitHub's action tab
CI in GitHub's action tab
After it finished I saw the following status with lots of encouraging tick marks…
 Encouraging tick marks
Encouraging tick marks
If one of them fails to have a tick mark you get an email saying the workflow failed
Expanding the run unit tests I saw cpputest testing my moving average class with all tests passing…
 Expanding the "Run unit tests" entry
Expanding the "Run unit tests" entry
In the summary of the workflow I see an artifact called “build.zip”…
 "build.zip" in summary
"build.zip" in summary
I downloaded this and ran it on kubuntu 20.04 which worked fine…
 Running the program built by GitHub
Running the program built by GitHub
It was quite cool that this ran on my computer without me having to even build it on my own computer.
I then went to actions CI and grabbed a status badge for the README.md file. This gave me a comforting “CI passing” badge…
 Added a continuous integration badge to the readme file
Added a continuous integration badge to the readme file
While this is very cool the moving average filter I wrote I might not use as is. Instead I think I will use either the STL (standard template library) or the Qt library to make things easier. Potentially portability to embedded devices might be difficult but I have absolutely no plan on moving this to anything embedded. So the next thing is making a moving stats library.
Moving stats library
I put together the moving stats library which can be seen at the following commit…
https://github.com/jontio/JSquelch/tree/763cf8b367308e488e4fe68cdbacc69cf2bc9548
I’ve put everything in the namespace of JDsp and added 4 classes; VectorMovingAverage, VectorMovingVariance, VectorMovingMax, and VectorMovingMin. They are all template classes and expect vectors as their input rather than things like double. I made them vectors inputs as the output from the FFT will be a vector so this will make things faster and easier. They say you should not repeat yourself in code but VectorMovingMin and VectorMovingMax are almost identical so might not be the best way of implementing them.
For the unit tests again there is a bit much repetition for my liking but oh well. I wanted to add a test that would pass successfully when the compiler failed due to illegal access but couldn’t figure out how that would be done; I’m not sure if there’s a way of doing this. What I mean is I would like the following code to pass the compiler failed to do this…
//this should fail
TEST(Test_DSP_VectorMovingMax, NoModifyDouble)
{
JDsp::VectorMovingMax<double> mv=JDsp::VectorMovingMax<double>(QPair<int,int>(4,3));
mv[1]=55;
}
I also only really checked the double versions of moving stats as I didn’t write the test code for the other two types of integer and complex. I don’t think complex would be defined for moving minimum and maximum anyway.
I added operator overriding to make these moving stats objects easy to use. The following shows an example of the usage of these classes for vectors of length four and a window of length five…
JDsp::VectorMovingVariance<double> mv(QPair<int,int>(4,5));
JDsp::VectorMovingMin<double> mm(QPair<int,int>(4,5));
JDsp::VectorMovingMax<double> mM(QPair<int,int>(4,5));
QVector<double> x={5,3,6,1};
qDebug()<<mm<<mM<<mv<<mv.mean();
for(int k=0;k<10;k++)
{
mm<<x;
mM<<x;
mv<<x;
qDebug()<<mm<<mM<<mv<<mv.mean();
x[0]+=1;
x[1]+=2;
}
This produces the following output…
Min(0, 0, 0, 0) Max(0, 0, 0, 0) Variance(0, 0, 0, 0) Mean(0, 0, 0, 0)
Min(0, 0, 0, 0) Max(5, 3, 6, 1) Variance(5, 1.8, 7.2, 0.2) Mean(1, 0.6, 1.2, 0.2)
Min(0, 0, 0, 0) Max(6, 5, 6, 1) Variance(9.2, 5.3, 10.8, 0.3) Mean(2.2, 1.6, 2.4, 0.4)
Min(0, 0, 0, 0) Max(7, 7, 6, 1) Variance(11.3, 9.5, 10.8, 0.3) Mean(3.6, 3, 3.6, 0.6)
Min(0, 0, 0, 0) Max(8, 9, 6, 1) Variance(9.7, 12.2, 7.2, 0.2) Mean(5.2, 4.8, 4.8, 0.8)
Min(5, 3, 6, 1) Max(9, 11, 6, 1) Variance(2.5, 10, 0, 0) Mean(7, 7, 6, 1)
Min(6, 5, 6, 1) Max(10, 13, 6, 1) Variance(2.5, 10, 0, 0) Mean(8, 9, 6, 1)
Min(7, 7, 6, 1) Max(11, 15, 6, 1) Variance(2.5, 10, 0, 0) Mean(9, 11, 6, 1)
Min(8, 9, 6, 1) Max(12, 17, 6, 1) Variance(2.5, 10, 0, 0) Mean(10, 13, 6, 1)
Min(9, 11, 6, 1) Max(13, 19, 6, 1) Variance(2.5, 10, 0, 0) Mean(11, 15, 6, 1)
Min(10, 13, 6, 1) Max(14, 21, 6, 1) Variance(2.5, 10, 0, 0) Mean(12, 17, 6, 1)
As the variance class calculates the average there is no need to use the average class if you’re already using the variance class.
I also noticed that using qDebug() causes cpputest to display memory leak errors which I don’t believe are actually happening.
FFT library
This one’s pretty easy for the FFT library I will use JFFT . I adjusted the github workflow to download the JFFT repo before building. I am really liking github’s actions it is so cool.
name: CI
# Controls when the action will run.
on:
# Triggers the workflow on push event but only for the main branch
#push:
# branches: [ main ]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- uses: actions/checkout@v2
with:
path: main
# Checks-out JFFT a needed depenancy
- name: Checkout FFT repo
uses: actions/checkout@v2
with:
repository: jontio/JFFT
path: JFFT
# Runs a single command using the runners shell
- name: Setup dependencies
run: |
sudo apt-get install qt5-default cpputest
# Runs a set of commands using the runners shell
- name: Run unit tests
run: |
cd main
qmake CONFIG+=CI
make
./jsquelch -v
echo finished testing.
# Build application
- name: Build application
run: |
cd main
make clean
qmake CONFIG-=CI
make
echo finished build.
# upload artifact
- name: Upload build
uses: actions/upload-artifact@v2
with:
name: build.zip
path: |
main/jsquelch
I had to write an interface for the FFT library as this voice detection algorithm needs to do some buffering windowing and padding. I still made it such that the FFT library required blocks of audio signal rather than an arbitrary number of frames.
At this point I realized the moving minimum class did not quite do what the algorithm wanted as the algorithm needs an associated value to that of the data being looked over to find the minimum. So I subclassed the moving minimum class and added functionality to keep track of an associated value. I called this class VectorMovingMinWithAssociate.
Moving Noise Estimator Class
I then created the moving noise estimator class that is subclassed from VectorMovingAverage. This class contained a moving variance class object, moving minimum with associate class object, as well as the moving average class to smooth the output. These three things a colored pale orange in the previous two block diagrams.
The following block diagram shows what classes the moving noise estimate class uses and how it uses them excluding QVector which is used by all classes…
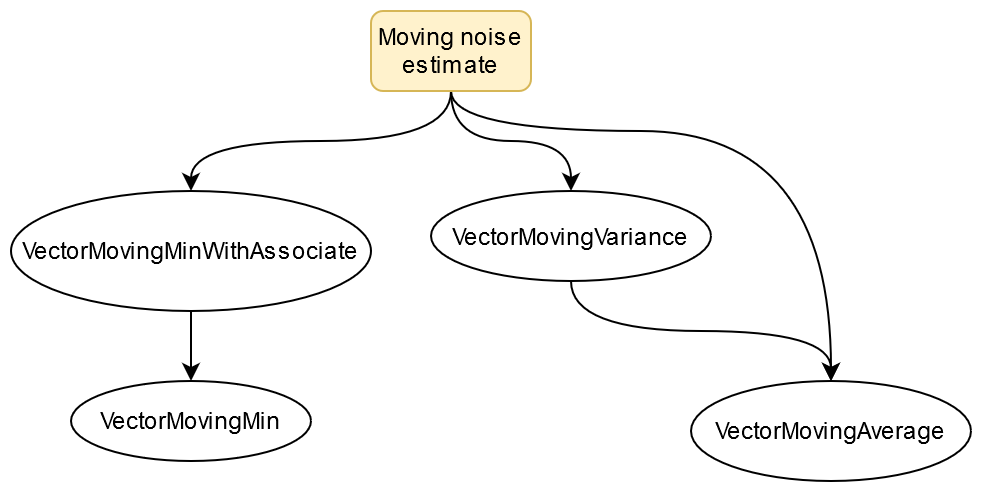 CI in GitHub's action tab
CI in GitHub's action tab
The moving noise estimator class along with the FFT class are used together in the following example where a random signal with a standard deviation of one is fed into the FFT…
//normally distributed numbers for the signal
std::default_random_engine generator(1);
std::normal_distribution<double> distribution(0.0,1.0);
JDsp::OverlappedRealFFT fft(3);//for an fft that takes 3 as in will output 2*3+1=7
QVector<double> x;//this would be the input signal split up into blocks
JDsp::MovingNoiseEstimator mne(fft.getOutSize(),16,16,32);
for(int k=0;k<640;k++)
{
x={distribution(generator),distribution(generator),distribution(generator)};
mne<<(fft<<x);
if((k+1)%64)continue;
qDebug()<<mne;
}
The x vector goes into the FFT and the output of that goes into the moving noise estimator. Finally every so often the noise estimate is written to the standard output…
Noise(1.00975, 1.01956, 1.04914, 1.10431, 1.12261, 1.13722, 1.16988)
Noise(1.22996, 1.22627, 1.23693, 1.23886, 1.25076, 1.29969, 1.30799)
Noise(1.00903, 1.07507, 1.19302, 1.30689, 1.363, 1.37509, 1.35586)
Noise(1.2335, 1.23451, 1.22991, 1.18543, 1.15753, 1.14204, 1.13511)
Noise(1.0106, 1.03077, 1.07481, 1.11599, 1.14903, 1.1484, 1.10748)
Noise(0.875575, 0.938062, 1.05466, 1.12679, 1.24008, 1.3088, 1.30957)
Noise(1.19341, 1.18137, 1.14924, 1.13763, 1.17851, 1.21613, 1.31142)
Noise(1.0965, 1.13382, 1.14679, 1.1303, 1.13517, 1.18505, 1.22808)
Noise(0.929295, 0.951046, 1.03854, 1.18444, 1.19993, 1.18092, 1.13159)
Noise(0.996635, 1.01634, 1.06267, 1.11054, 1.12922, 1.10954, 1.05887)
As you can see each frequency bin has a noise of about 1 which the same as the standard deviation of the signal in the time domain.
I pushed all this and tested out the github workflow and everything seems to be working fine. You can see this push here…
https://github.com/jontio/JSquelch/tree/2a8813aeeeeeb20788422ded18aea3553025306a
By this point I had 10 files for the unit tests; one for each class. I’ve always written testing code but usually just delete it once I know something works. The good thing about having a folder full of unit tests is it documents the tests I’ve tried and they can be run in the future if me or anyone else wants to refactor the code at a later date they can do so without as much trepidation.
Yet more classes ARGHHHHHH!!!!
By about this time I was getting pissed off writing endless classes and test units. So far I have written the following classes in the JDsp namespace…
Hann
StrangeSineCorrectionWindow
VectorDelayLine
VectorMovingAverage
VectorMovingVariance
VectorMovingMax
VectorMovingMin
VectorMovingMinWithAssociate
OverlappedRealFFT
OverlappedRealFFTDelayLine
InverseOverlappedRealFFT
MovingNoiseEstimator
Normalize
MovingAverage
MovingSignalEstimator
All of them but VectorMovingMax are used for the algorithm. I had to write a delay line class as the moving functions of Matlab is slightly different than mine; this was expected. Another class that I will end up having to write is an AGC class as the output of the algorithm will produce audio that may saturate. I didn’t write test units for the delay lines as I was getting really pissed off doing that all the time.
It’s taken about 10 days of coding every day to get to write all the classes, test units, Matlab scripts and helper functions.
In the Matlab folder https://github.com/jontio/JSquelch/tree/main/matlab the script create_signal.m will run the algorithm using the wave file untitled_8khz.wav to create various test data for the matlab_compare_tests.cpp test unit. If the test unit is run with a define called GENERATE_FILES_FOR_MATLAB then it will create various Matlab files which can be compared with the algorithm in Matlab using the script compare_signal.m. The output of this script displays the following figures…
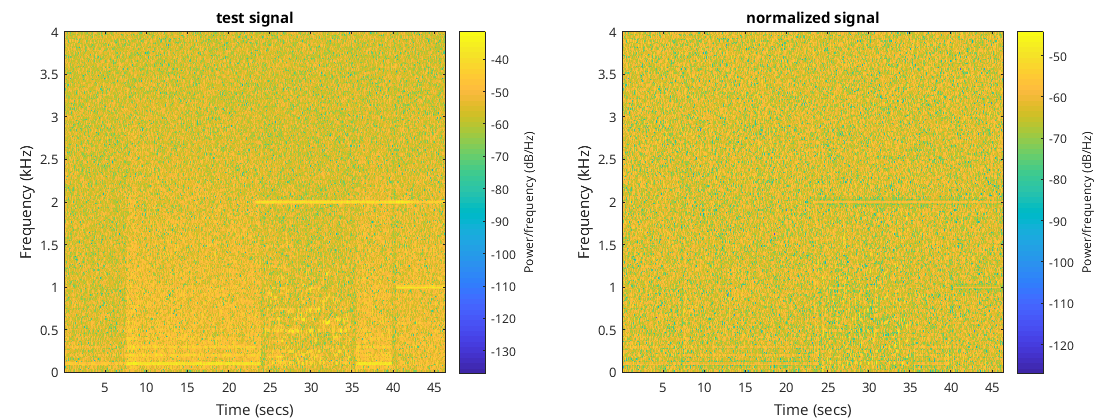
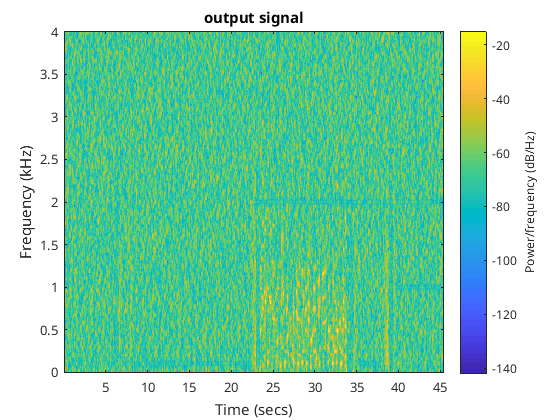
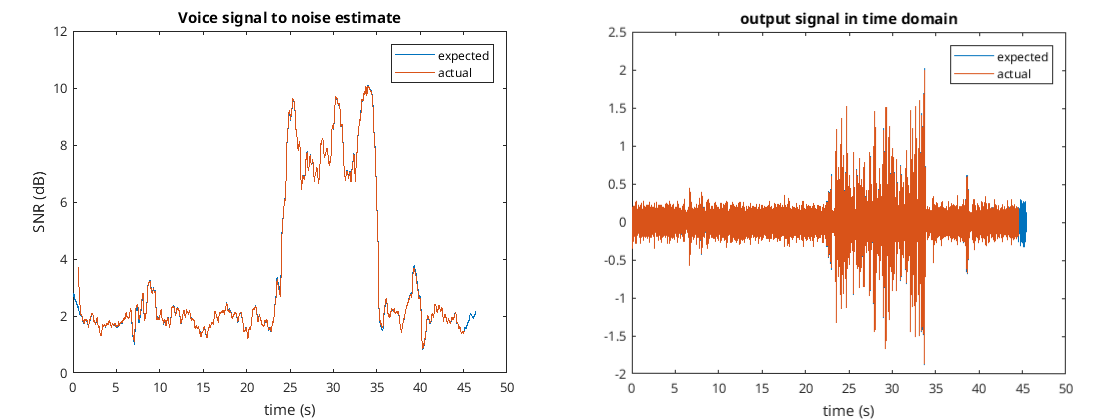
The second to last figure show the estimated SNR from both Matlab and C++ implementations of the algorithm. The final figure shows the audio output from both of the implementations of the algorithm. As you can see they match very well.
As you can also see the audio output goes above one which would clip so I’ll have to think of some sort of AGC for that.
The algorithm using all the classes in the namespace JDsp can be written along the following lines…
JDsp::OverlappedRealFFT fft(128);
JDsp::MovingNoiseEstimator mne(fft.getOutSize(),16,16,62);
JDsp::MovingSignalEstimator mse(fft.getOutSize(),8,3,96,62,8);
JDsp::InverseOverlappedRealFFT ifft(fft.getInSize());
JDsp::OverlappedRealFFTDelayLine fft_delay1(fft,51);
JDsp::OverlappedRealFFTDelayLine fft_delay2(fft,6);
//do algo
fft<<x;//signal in
mne<<fft;//output of fft to input of mne
fft_delay1.delay(fft);//1st delayline to match matlab
fft/=mne;//normalize output of fft
mse<<fft;//output of fft into mse
fft_delay2.delay(fft);//2nd delayline to match matlab
fft*=mse;//scale fft output by signal estimate
ifft<<fft;//output of fft to inverse fft to produce reconstructed signal
The output signal is ifft while the estimated SNR is mse.voice_snr_estimate.
Anyway back to it. Hopefully I’ll manage to finish the algorithm soon so I can move on to the I/O stuff as well as the GUI.
The algorithm class
For the AGC I created a moving maximum class for the audio output and divided the audio output by this value, hopefully that’s good enough.
I added yet more classes to the JDsp library, so far I’m up to the following…
Hann
StrangeSineCorrectionWindow
VectorDelayLine
ScalarDelayLine
VectorMovingAverage
VectorMovingVariance
VectorMovingMax
MovingMax
VectorMovingMin
VectorMovingMinWithAssociate
OverlappedRealFFT
OverlappedRealFFTDelayLine
InverseOverlappedRealFFT
InverseOverlappedRealFFTDelayLine
MovingNoiseEstimator
Normalize
MovingAverage
MovingSignalEstimator
I have also added a class that implements the algorithm which I call VoiceDetectionAlgo. It has some input buffering so doesn’t care about the size of the vector given to it this is the sort of thing you have to do…
//run algo over file
while(!file.atEnd())
{
//read some audio
for(int i=0;i<x.size();i++)
{
if(file.atEnd())break;
datastream>>x[i];
}
if(file.atEnd())break;
//add the audio to the algo
algo+=x;
//process the audio wile we have some
while(!algo.process().empty())
{
//skip nan blocks
if(isnan(algo.snr_db))continue;
//keep snr_db
actual_snr_estimate_db_signal+=algo.snr_db;
//keep output signal when snr_db is good
if(algo.snr_db<5.0) continue;
actual_output_signal+=algo.ifft;
}
}
file.close();
I have written lots unit tests and so far it seems to work as expected. A couple of the unit tests will generate audio from the input test audio file called test_signal_time.raw in the Matlab folder and output this to the test_output folder which will be created when the unit tests are run. The current commit can be found here
https://github.com/jontio/JSquelch/tree/0d93cc7b338d7740a9bf6b059390f04c04acb2a9
So far 13 days of writing and test C++ every day say 5 to 8 hours a day to get to the stage. The next stage is getting the audio input and output connected to the algorithm. Anyway back to it.
Day 19
After six more days of writing C++ code I have something that is good enough for me. I got rid of the noise reduction thing with the reconstituting of the FFT signal as it meant I had deal with more settings and I was having issues with the AGC. So now the algorithm is simpler…
QVector<double> &VoiceDetectionAlgo::process()
{
//if we dont have enough in the buffer then return an empty vector
if(buffer.size()<fft.getInSize())
{
empty.clear();
return empty;
}
QVector<double>::operator=(buffer.mid(0,fft.getInSize()));
buffer.remove(0,fft.getInSize());
//do main algo
fft<<(*this);//signal in
mne<<fft;//output of fft to input of mne. calculates noise
fft_delay.delay(fft);//fft delayline
fft/=mne;//normalize output of fft
mse<<fft;//output of fft into mse. calculates signal
snr_db_pre_delayline=10.0*log10(mse.voice_snr_estimate);//convert snr to db
snr_db=snr_db_pre_delayline;
snr_db_delayline.delay(snr_db);//delay snr
//delay the audio to align with snr_db and return the audio
audio_out_delayline.delay(*this);
return *this;
}
I added the ability for the audio output to be saved to an ogg audio file in the opus compression format. I added some control of the settings from the main window along with settings persistence. Added some form layout to the window, some hysteresis, and an AGC.
For the audio loopback class I subclassed QIODevice and used QAudioInput and QAudioOutput (part of QMultimedia). Sometimes I use RTaudio and other times QMultimedia. One problem with audio loopbacks where the input device uses a different clock than the output device, is that as the clocks are not identical eventually you either get an overflow or an underrun which will cause an audible click. I don’t have a particularly nice way of solving this problem. If I ignore it for a couple of my soundcards I have I calculated it would take about a day for an overflow to happen at 8 kHz and a 4000 circular buffer, that’s not too much of a big deal. However I decided to add some code that would linearly interpolate the samples and remove or insert samples slowly over time so as not to produce a clicking sound. If I had rapidly inserted or removed a sample you unavoidably end up getting an audible clicking sound. Slowly inserting a sample or removing a sample can produce a slight whooshing sound but I think I’ve got it so it’s not too obvious. Anyway one day it would be nice to come back to this issue and see if there’s a better way as quite often I need a loopback class where I can process the samples in between.
I updated the continuous integration Yaml file and everything is passing. I also fixed a couple of things that were a bit out on the Windows build.
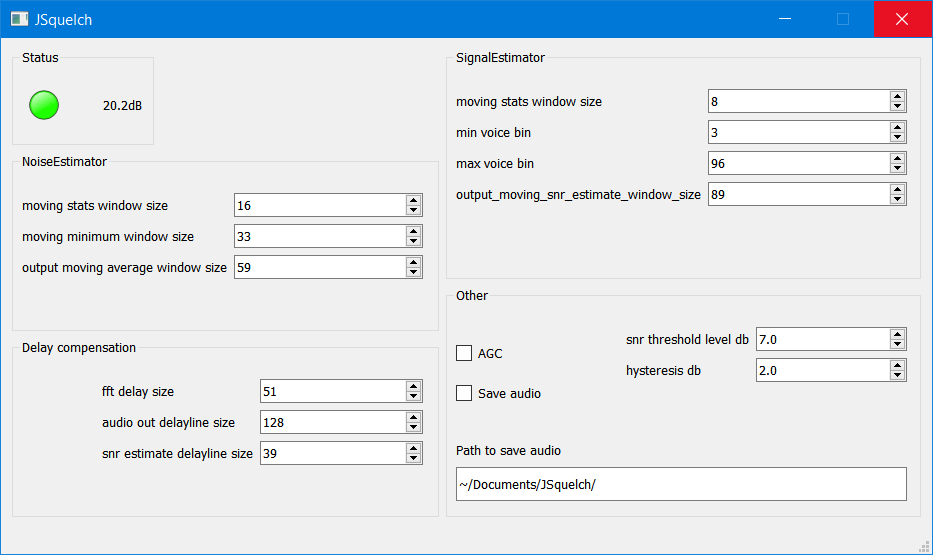 Final application running on Windows
Final application running on Windows
If we look back to the initial requirements we see that all requirements apart from “voice detection algorithm as described” are met…
- GUI
- audio input and output via soundcard driver
voice detection algorithm as described- user can change most settings of the voice detection algorithm
- persistent settings
- LED signifying voice present
- audio output to soundcard only happens when voice is present
- audio can be saved to disk
The voice detection algorithm changed from the described one as I removed the reconstitution part of the algorithm as I was having trouble getting the audio output level right and didn’t want spend more time on it. However the detection part of the algorithm itself is still as described.
I’ve spent way too long on this already. Others, perhaps yourself, will have to deal with issues and packaging which I don’t want to do myself. It’s time for me to move on to the next project.
Jonti 2021
Home